The Language Instinct: How the Mind Creates Language (29 page)
Read The Language Instinct: How the Mind Creates Language Online
Authors: Steven Pinker

Syllables and feet are classified as strong (s) and weak (w) by other rules, and the pattern of weak and strong branches determines how much stress each syllable will be given when it is pronounced. Feet, like onsets and rhymes, are salient chunks of word that we tend to manipulate in poetry and wordplay. Meter is defined by the kind of feet that go into a line. A succession of feet with a strong-weak pattern is a trochaic meter, as in
Mary had a little lamb;
a succession with a weak-strong pattern is iambic, as in
The rain in Spain falls mainly in the plain
. An argot popular among young ruffians contains forms like
fan-fuckin-tastic, abso-bloody-lutely, Phila-fuckin-delphia
, and
Kalama-fuckin-zoo
. Ordinarily, expletives appear in front of an emphatically stressed word; Dorothy Parker once replied to a question about why she had not been at the symphony lately by saying “I’ve been too fucking busy and vice versa.” But in this lingo they are placed inside a single word, always in front of a stressed foot. The rule is followed religiously:
Philadel-fuckin-phia
would get you launched out of the pool hall.
The assemblies of phonemes in the morphemes and words stored in memory undergo a series of adjustments before they are actually articulated as sounds, and these adjustments give further definition to the sound pattern of a language. Say the words
pat
and
pad
. Now add the inflection -
ing
and pronounce them again:
patting, padding
. In many dialects of English they are now pronounced identically; the original difference between the
t
and the
d
has been obliterated. What obliterated them is a phonological rule called flapping: if a stop consonant produced with the tip of the tongue appears between two vowels, the consonant is pronounced by flicking the tongue against the gum ridge, rather than keeping it there long enough for air pressure to build up. Rules like flapping apply not only when two morphemes are joined, like
pat
and -
ing;
they also apply to one-piece words. For many English speakers
ladder
and
latter
, though they “feel” like they are made out of different sounds and indeed are represented differently in the mental dictionary, are pronounced the same (except in artificially exaggerated speech). Thus when cows come up in conversation, often some wag will speak of an udder mystery, an udder success, and so on.
Interestingly, phonological rules apply in an ordered sequence, as if words were manufactured on an assembly line. Pronounce
write
and
ride
. In most dialects of English, the vowels differ in some way. At the very least, the
i
in
ride
is longer than the
i
in
write
. In some dialects, like the Canadian English of newscaster Peter Jennings, hockey star Wayne Gretzky, and yours truly (an accent satirized a few years back, eh, in the television characters Bob and Doug McKenzie), the vowels are completely different:
ride
contains a diphthong gliding from the vowel in
hot
to the vowel
ee; write
contains a diphthong gliding from the higher vowel in
but
to
ee
. But regardless of exactly how the vowel is altered, it is altered in a consistent pattern: there are no words with long/low
i
followed by
t
, nor with short/high
i
followed by
d
. Using the same logic that allowed Lois Lane in her rare lucid moments to deduce that Clark Kent and Superman were the same, namely that they are never in the same place at the same time, we can infer that there is a single
i
in the mental dictionary, which is altered by a rule before being pronounced, depending on whether it appears in the company of
t
or
d
. We can even guess that the initial form stored in memory is like the one in
ride
, and that
write
is the product of the rule, rather than vice versa. The evidence is that when there is no
t
or
d
after the
i
, as in
rye
, and thus no rule disguising the underlying form, it is the vowel in
ride
that we hear.
Now pronounce
writing
and
riding
. The
t
and
d
have been made identical by the flapping rule. But the two
i
’s are still different. How can that be? It is only the difference between
t
and
d
that causes a difference between the two
i
’s, and that difference has been erased by the flapping rule. This shows that the rule that alters
i
must have applied
before
the flapping rule, while
t
and
d
were still distinct. In other words, the two rules apply in a fixed order, vowel-change before flapping. Presumably the ordering comes about because the flapping rule is in some sense there to make articulation easier and thus is farther downstream in the chain of processing from brain to tongue.
Notice another important feature of the vowel-altering rule. The vowel
i
is altered in front of many different consonants, not just
t
. Compare:
prize price
five fife
jibe hype
geiger biker
Does this mean there are five different rules that alter
i
—one for
z
versus
s
, one for
v
versus
f
, and so on? Surely not. The change-triggering consonants
t, s, f, p
, and
k
all differ in the same way from their counterparts
d, z, v, b
, and
g:
they are unvoiced, whereas the counterparts are voiced. We need only one rule, then: change
i
whenever it appears before an
unvoiced
consonant. The proof that this is the real rule in people’s heads (and not just a way to save ink by replacing five rules with one) is that if an English speaker succeeds in pronouncing the German
ch
in the
Third Reich
, that speaker will pronounce the
ei
as in
write
, not as in
ride
. The consonant
ch
is not in the English inventory, so English speakers could not have learned any rule specifically applying to it. But it is an unvoiced consonant, and if the rule applies to any unvoiced consonant, an English speaker knows exactly what to do.
This selectivity works not only in English but in all languages. Phonological rules are rarely triggered by a single phoneme; they are triggered by an entire class of phonemes that share one or more features (like voicing, stop versus fricative manner, or which organ is doing the articulating). This suggests that rules do not “see” the phonemes in a string but instead look right through them to the features they are made from.
And it is features, not phonemes, that are manipulated by the rules. Pronounce the following past-tense forms:
walked
slapped
passed
jogged
sobbed
fizzed
In
walked, slapped
, and
passed
, the -
ed
is pronounced as a
t;
in
jogged, sobbed
, and
fizzed
, it is pronounced as a
d
. By now you can probably figure out what is behind the difference: the t pronunciation comes after voiceless consonants like
k, p
, and s; the
d
comes after voiced ones like
g, b
, and
z
. There must be a rule that adjusts the pronunciation of the suffix -
ed
by peering back into the final phoneme of the stem and checking to see if it has the voicing feature. We can confirm the hunch by asking people to pronounce
Mozart out-Bached Bach
. The verb
to out-Bach
contains the sound
ch
, which does not exist in English. Nonetheless everyone pronounces the -
ed
as a
t
, because the
ch
is unvoiced, and the rule puts a
t
next to any unvoiced consonant. We can even determine whether people store the -
ed
suffix as a
t
in memory and use the rule to convert it to a
d
for some words, or the other way around. Words like
play
and
row
have no consonant at the end, and everyone pronounces their past tenses like
plade
and
rode
, not
plate
and
rote
. With no stem consonant triggering a rule, we must be hearing the suffix in its pure, unaltered form in the mental dictionary, that is,
d
. It is a nice demonstration of one of the main discoveries of modern linguistics: a morpheme may be stored in the mental dictionary in a different form from the one that is ultimately pronounced.
Readers with a taste for theoretical elegance may want to bear with me for one more paragraph. Note that there is an uncanny pattern in what the
d
-to-
t
rule is doing. First,
d
itself is voiced, and it ends up next to voiced consonants, whereas
t
is unvoiced, and it ends up next to unvoiced consonants. Second, except for voicing,
t
and
d
are the same; they use the same speech organ, the tongue tip, and that organ moves in the same way, namely sealing up the mouth at the gum ridge and then releasing. So the rule is not just tossing phonemes around arbitrarily, like changing a
p
to an
l
following a high vowel or any other substitution one might pick at random. It is doing delicate surgery on the -
ed
suffix, adjusting it to be the same in voicing as its neighbor, but leaving the rest of its features alone. That is, in converting
slap + ed
to
slapt
, the rule is “spreading” the voicing instruction, packaged with the
p
at the end of
slap
, onto the -
ed
suffix, like this:
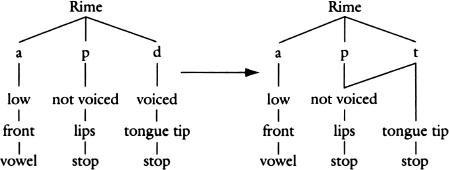
The voicelessness of the
t
in
slapped
matches the voicelessness of the
p
in
slapped
because they are the
same
voicelessness; they are mentally represented as a single feature linked to two segments. This happens very often in the world’s languages. Features like voicing, vowel quality, and tones can spread sideways or sprout connections to several phonemes in a word, as if each feature lived on its own horizontal “tier,” rather than being tethered to one and only one phoneme.
So phonological rules “see” features, not phonemes, and they adjust features, not phonemes. Recall, too, that languages tend to arrive at an inventory of phonemes by multiplying out the various combinations of some set of features. These facts show that features, not phonemes, are the atoms of linguistic sound stored and manipulated in the brain. A phoneme is merely a bundle of features. Thus even in dealing with its smallest units, the features, language works by using a combinatorial system.