XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (151 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

Usage and Examples
There are two principal uses for
Copying Nodes to and from Temporary Trees
One use of
Example: Using
This example constructs a table heading in a variable and then copies it repeatedly each time a new table is created.
Source
The source file
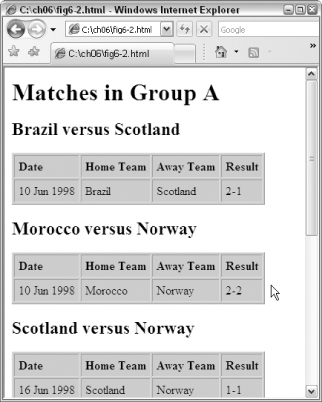
soccer.xml
holds details of a number of soccer matches played during the World Cup finals in 1998.
Stylesheet
The stylesheet is in the file
soccer.xsl
.
It constructs an HTML table heading as a global tree-valued variable, and then uses
xmlns:xsl=“http://www.w3.org/1999/XSL/Transform”>
Date Home Team Away Team Result
Matches in Group
select=“format-date(date, ‘[D] [MNn,1-3] [Y]’)”/> select=“team[1]/@score, ‘-’, team[2]/@score” separator=“”/>
Output
(Apologies to soccer fans who know that all these matches were played in France, on neither team's home territory. It's only an example!) See
Figure 6-2
.
Deep Copy
The other use for
Unlike the examples using
The most common example of this technique is using
Copying all the attributes with specific exceptions is also straightforward using the new except
except operator in XPath 2.0:
operator in XPath 2.0:
Using
Copying Namespace Nodes
The
copy-namespaces
attribute provides a choice as to whether the namespace nodes in a tree are copied or not. By default, all the namespaces are copied.
If namespaces are used only in the names of elements and attributes, then there is no need to copy namespace nodes. In the new tree, all the necessary namespace nodes will be created by virtue of the namespace fixup process, which is described under
The real problem arises when namespace prefixes are used in the values of attributes or text nodes. This happens, for example, if the document is an XSLT stylesheet containing XPath expressions, if it is an XML Schema, if it usesxsi:typeattributes that identify schema-defined types (the value of this attribute is a QName, and therefore contains a namespace prefix), or if it uses any other XML vocabulary that contains references to the names of elements or attributes within the document content. Since the XSLT processor cannot know that these references exist, and since the references depend on the existence of namespace nodes to resolve namespace prefixes to a URI, it is unsafe to shed the namespace nodes.
There are some cases where losing namespace nodes is very desirable. For example, if an XML document is wrapped in a SOAP envelope and then subsequently removed from the envelope, the round trip can easily cause the SOAP namespaces defined for use in the envelope to stick to the content when it is extracted usingcopy-namespaces=“no”can be useful to remove unwanted namespaces from the result. But it is only safe to use this option if you know that there are no namespace prefixes in the content of text nodes and attribute nodes.