Another attempt appears in the specification of Canonical XML (
http://www.w3.org/TR/xml-c14n
). This specification approaches the question by defining a transformation that can be applied to any XML document to turn it into canonical form, and if two documents have the same canonical form, they are considered equivalent.
The process of turning a document into canonical form is summarized as follows:
1.
The document is encoded in UTF-8.
2.
Line breaks are normalized to
x0A
.
3.
Attribute values are normalized, depending on the attribute type.
4.
Character references and parsed entity references are expanded.
5.
CDATA sections are replaced with their character content.
6.
The XML declaration and document type declaration (DTD) are removed.
7.
Empty element tags (
) are converted to tag pairs (
).
8.
Whitespace outside the document element and within tags is normalized.
9.
Attribute value delimiters are set to double quotes.
10.
Special characters in attribute values and character content are replaced by character references.
11.
Redundant namespace declarations are removed.
12.
Default attribute values defined in the DTD are added to each element.
13.
Attributes and namespace declarations are sorted into alphabetical order.
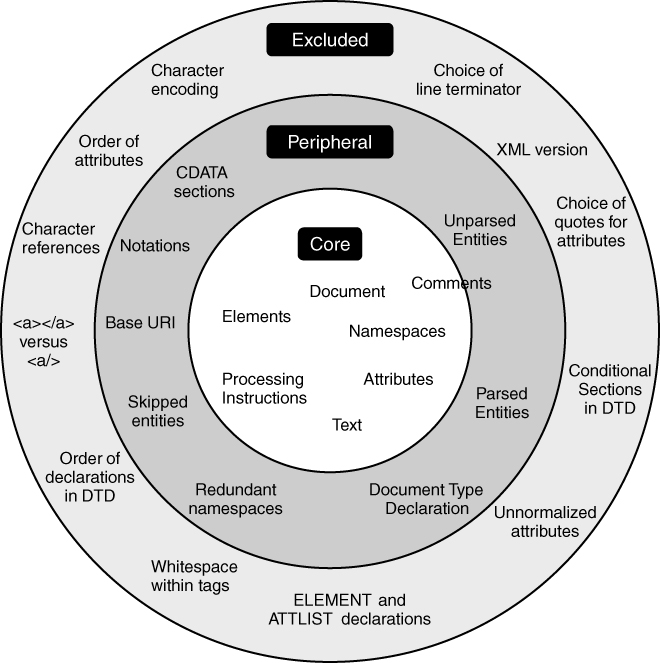
Canonical form discards some of the original content that the InfoSet retains, for example CDATA sections. However, this specification has a gray area too: canonical form may or may not retain comments from the original document.
XDM leans more towards the minimalist view of the Canonical XML specification.
Figure 2-8
illustrates the resulting classification: the central core is information that is retained in canonical form (comments being on the boundary since the spec leaves the question open); the “peripheral” ring is information that is present in the Infoset but not in canonical XML, while the outer ring represents features of an XML document that are also excluded from the InfoSet. XDM sticks essentially to the Core features (including comments), with a couple of minor additions: XSLT also recognizes unparsed entities, and also makes available the base URI (which is a rather peculiar property, since it can't actually be determined from the content of the XML document, only from its location).
From Textual XML to a Data Model
I've explained the data model so far in this chapter by relating the constructs in XDM (such as element nodes and text nodes) to constructs in a textual XML document. This isn't actually how the W3C specs define it. There are two important differences:
- The W3C specifications don't describe the model in terms of textual XML; they describe it in terms of the XML Infoset, as mentioned in the previous section, together with the PSVI (Post Schema Validation Infoset), which describes an augmented Infoset containing not only the information in the raw XML but also the additional information that becomes available as a result of schema validation.
- Although the W3C specifications describe a mapping from the Infoset and PSVI to XDM, this mapping is non-normative (which is standards-speak for saying that it's not officially part of the standard). Products aren't required to provide any particular way of constructing the XDM tree from raw XML. This was also true in XSLT 1.0, and it is an issue that has caused some controversy, because it means there is no guarantee that two XSLT processors will give the same answer when applied to the same source document.
- The main reason for putting this mapping outside the conformance boundary of the specification is to allow XPath and XSLT to be used in as wide a variety of contexts as possible, for example in environments where the data model is not constructed from textual XML at all, but is rather a view of non-XML information. Unfortunately, this also means that where the data model is constructed in the conventional way by parsing textual XML files, different processors are allowed to do it in different ways.
Examples of the variations that have arisen in this area between different 1.0 processors are:
- The standard way of building a data model using Microsoft's MSXML processor, if all options are set to their default values, causes whitespace-only text nodes to be removed from the model. The standard mapping keeps these nodes present. Microsoft's decision has some rationale: in many cases the extra whitespace nodes simply get in the way; they make the XPath user's life more difficult, and they take up space for no useful reason. Unfortunately, there are some cases where the whitespace is actually significant, and more importantly, this decision means that it's not uncommon for an XSLT stylesheet to produce a different result under MSXML than the result produced under every other processor.
- One XSLT vendor (Fourthought: see
www.fourthought.com
) decided that it would be a good idea to expand any XInclude directives in the source XML as part of the process of building the data model. There is nothing in the spec to say whether XInclude should be expanded or not, and it's something that some users might want to happen and other users might not want to happen. So they were entirely within their rights to make this decision. But again, it creates a problem because different processors are no longer compatible.
XDM leaves additional scope for variations between processors. Because the model is designed to support XQuery as well as XSLT, the range of possible usage scenarios is greatly increased. Many XQuery vendors aim to offer implementations capable of searching databases containing hundreds of gigabytes of data, and in such environments performance optimization becomes a paramount requirement. In fact, database products have traditionally treated performance as a more important quality than standards conformance, and there are indications that this culture is present among some of the XQuery vendors. Examples of the kind of variations that may be encountered include the following:
- Dropping of whitespace text nodes (again!).
- Storing only the typed value of elements and attributes, and not the string value.
- Dropping comments and processing instructions.
- Dropping unused namespace declarations.
It remains to be seen how most vendors will handle these problems. Hopefully, vendors will offer any optimizations as an option that the user can choose, rather than as the default way that source XML is processed when loading the data.
Controlling Serialization
The transformation processor, which generates the result tree, generally gives the user control only over the core information items and properties (including comments) in the output. The output processor or serializer gives a little bit of extra control over how the result tree is converted into a serial XML document. Specifically, it allows control over the following:
- Generation of
CDATA
sections
- XML version
- Character encoding
- The
standalone
property in the XML declaration
- DOCTYPE
declaration
Although you get some control over these features during serialization, one thing you can't do is copy them from the source document unchanged through to the result. The fact that text was in a
CDATA
section in the input document has no bearing on whether it will be represented as a
CDATA
section in the output document. The tree model does not provide any way for this extra information to be retained.
The Transformation Process
I've described the essential process performed by XSLT, transformation of a source tree to a result tree under the control of a stylesheet, and looked at the structure of these trees. Now it's time to look at how the transformation process actually works, which means taking a look inside the stylesheet.
Invoking a Transformation
The actual interface for firing off a transformation is outside the scope of the XSLT specification, and it's done differently by different products. There are also different styles of interface: possibilities include an API that can be invoked by applications, a GUI interface within a development environment, a command line interface, an interface from a pipeline processor such as XProc or a build tool such as
ant
, as well as the use of an
processing instruction within a source document, which is described in Chapter 3 (see page 99). There's a common API for Java processors that was initially called TrAX, then became part of JAXP, and since JDK 1.4 has been part of the standard Java class library. For browsers, Microsoft and Firefox each have their own API, but there is at least one project (Sarissa, see
http://sarissa.sourceforge.net/
) that provides a common API that can be used on both these browsers as well as Opera, Safari, and Konqueror.
What the XSLT 2.0 specification does do is to describe in abstract terms what information can be passed across this interface when the transformation is started. This includes the following:
- The stylesheet itself
: Many products provide separate API calls to compile a stylesheet and then to run it, which saves time if the same stylesheet is being used to transform many source documents.
- A source document
: This can be identified by any node in the document, which acts as the initial context node for the transformation. This will usually be the document node at the root of the tree, but it doesn't have to be. In fact, you don't have to supply an initial context node at all; the stylesheet can then fetch any data it needs from stylesheet parameters or from calls on the
document()
function.
- An initial named template
: This acts as the entry point to the stylesheet and is needed when you don't supply an initial context node, but it is also possible to supply both. If an initial named template is identified, the transformation starts with that template; otherwise, it starts by searching for a template rule that matches the initial context node, as described in the next section.
- An initial mode
: Modes are described later in this chapter, on page 78. Normally, the transformation starts in the default (unnamed) mode, but you can choose to start in a different mode if you prefer. When the template rules in a stylesheet use a named mode, it becomes easier to combine two stylesheets into a single multiphase transformation, as described on page 85, and this feature ensures that you can still use the rules for each processing phase independently.
- Parameters
: A stylesheet can define global parameters using
elements, as discussed on page 425. Interfaces for invoking a transformation will generally provide some kind of mechanism for setting values for these parameters. (A notable exception is that when you invoke a transformation using the
processing instruction in a source document, there is usually no way of setting parameters.)
- A base URI for output documents
: Many stylesheets will produce a single result document, and this URI effectively defines where this result document will be written. If the stylesheet produces multiple result documents, then each one is created using an
instruction with an
href
attribute, and the
href
attribute, if it is relative, is interpreted as a location relative to this base URI.
Template Rules
As we saw in Chapter 1, most stylesheets will contain a number of template rules. Each template rule is expressed in the stylesheet as an
element with a
match
attribute. The value of the
match
attribute is a pattern. The pattern determines which nodes in the source tree the template rule matches.
For example, the pattern
 /
/
 matches the document node, the pattern
matches the document node, the pattern
title
matches a
<br/></span>element, and the pattern<br/><span><img src="/files/04/27/65/f042765/public/ll.gif" />chapter/title<br/><img src="/files/04/27/65/f042765/public/gg.gif" /></span>matches a<br/><span><title><br/></span>element whose parent is a<br/><span><chapter><br/></span>element.<br/></p></div> </div>
<div class="col-xs-12 text-left pagination-container">
<ul class="pagination"><li class="prev"><a href="/english-books/full-book-xslt-20-and-xpath-20-programmers-reference-4th-edition-read-online-chapter-27" data-page="26">«</a></li>
<li class="first"><a href="/english-books/full-book-xslt-20-and-xpath-20-programmers-reference-4th-edition-read-online" data-page="0">1</a></li>
<li class="disabled"><span>...</span></li>
<li><a href="/english-books/full-book-xslt-20-and-xpath-20-programmers-reference-4th-edition-read-online-chapter-12" data-page="11">12</a></li>
<li class="disabled"><span>...</span></li>
<li><a href="/english-books/full-book-xslt-20-and-xpath-20-programmers-reference-4th-edition-read-online-chapter-23" data-page="22">23</a></li>
<li><a href="/english-books/full-book-xslt-20-and-xpath-20-programmers-reference-4th-edition-read-online-chapter-24" data-page="23">24</a></li>
<li><a href="/english-books/full-book-xslt-20-and-xpath-20-programmers-reference-4th-edition-read-online-chapter-25" data-page="24">25</a></li>
<li><a href="/english-books/full-book-xslt-20-and-xpath-20-programmers-reference-4th-edition-read-online-chapter-26" data-page="25">26</a></li>
<li><a href="/english-books/full-book-xslt-20-and-xpath-20-programmers-reference-4th-edition-read-online-chapter-27" data-page="26">27</a></li>
<li class="active"><a href="/english-books/full-book-xslt-20-and-xpath-20-programmers-reference-4th-edition-read-online-chapter-28" data-page="27">28</a></li>
<li><a href="/english-books/full-book-xslt-20-and-xpath-20-programmers-reference-4th-edition-read-online-chapter-29" data-page="28">29</a></li>
<li><a href="/english-books/full-book-xslt-20-and-xpath-20-programmers-reference-4th-edition-read-online-chapter-30" data-page="29">30</a></li>
<li><a href="/english-books/full-book-xslt-20-and-xpath-20-programmers-reference-4th-edition-read-online-chapter-31" data-page="30">31</a></li>
<li><a href="/english-books/full-book-xslt-20-and-xpath-20-programmers-reference-4th-edition-read-online-chapter-32" data-page="31">32</a></li>
<li class="disabled"><span>...</span></li>
<li><a href="/english-books/full-book-xslt-20-and-xpath-20-programmers-reference-4th-edition-read-online-chapter-467" data-page="466">467</a></li>
<li class="disabled"><span>...</span></li>
<li class="last"><a href="/english-books/full-book-xslt-20-and-xpath-20-programmers-reference-4th-edition-read-online-chapter-901" data-page="900">901</a></li>
<li class="next"><a href="/english-books/full-book-xslt-20-and-xpath-20-programmers-reference-4th-edition-read-online-chapter-29" data-page="28">»</a></li></ul> </div>
<div class=""><div class="col-xs-12"><h2>Other books</h2></div><div class="list-b-item col-xs-12 col-md-6"><svg enable-background="new 0 0 512 512" viewBox="0 0 512 512" xmlns="http://www.w3.org/2000/svg">
<g>
<path d="m419.17 410.104v62.4h-288.17c-11.87 0-21.5-9.63-21.5-21.5v-19.4c0-11.87 9.63-21.5 21.5-21.5z" fill="#d9ecfd"/>
<path d="m419.17 441.304v31.2h-288.17c-11.87 0-21.5-9.63-21.5-21.5v-9.7z" fill="#c5e2ff"/>
<path d="m132.68 378.104v-370.604h-20.18c-19.33 0-35 15.67-35 35v389.104c0-29.645 24.103-53.64 53.748-53.506z" fill="#db3915"/>
<path d="m132.68 7.5h301.82v370.604h-301.82z" fill="#fc5a36"/><path d="m131 378.104c-29.547 0-53.5 23.953-53.5 53.5v19.396c0 29.547 23.953 53.5 53.5 53.5h303.5v-32h-303.5c-11.874 0-21.5-9.626-21.5-21.5v-19.396c0-11.874 9.626-21.5 21.5-21.5h303.5v-32z" fill="#a42b0f"/>
<path d="m193.467 63.104h180.382v80.72h-180.382z" fill="#ffc85e"/>
<g>
<path d="m434.5 0h-322c-23.435 0-42.5 19.059-42.5 42.485v408.515c0 33.635 27.364 61 61 61h303.5c4.143 0 7.5-3.358 7.5-7.5v-32c0-4.142-3.357-7.5-7.5-7.5h-7.83v-47.396h7.83c4.143 0 7.5-3.358 7.5-7.5v-402.604c0-4.142-3.358-7.5-7.5-7.5zm-349.5 42.485c0-15.155 12.337-27.485 27.5-27.485h12.68v263.534c0 4.142 3.357 7.5 7.5 7.5s7.5-3.358 7.5-7.5v-263.534h286.82v355.604h-286.82v-59.38c0-4.142-3.357-7.5-7.5-7.5s-7.5 3.358-7.5 7.5v59.664c-15.988 1.521-30.186 9.242-40.18 20.721zm326.67 391.319h-53.67c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h53.67v16.196h-280.67c-9.167 0-14.875-7.396-14-16.196h208.31c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5h-208.31c-.875-9.45 4.831-16.2 14-16.2h280.67zm15.33-31.2h-296c-15.99 0-29 13.009-29 29v19.396c0 15.991 13.01 29 29 29h296v17h-296c-25.364 0-46-20.636-46-46v-19.396c0-25.364 20.636-46 46-46h296z"/><path d="m193.469 151.324h180.38c4.143 0 7.5-3.358 7.5-7.5v-80.72c0-4.142-3.357-7.5-7.5-7.5h-45.349c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h37.85v65.72h-165.38v-65.72h94.84c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5h-102.34c-4.143 0-7.5 3.358-7.5 7.5v80.72c-.001 4.142 3.357 7.5 7.499 7.5z"/>
<path d="m341.658 241.592h-116c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h116c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5z"/><path d="m341.658 277.409h-116c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h116c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5z"/>
</g>
</g>
</svg><div><a href="/english-books/full-book-red-beans-and-vice-read-online">Red Beans and Vice</a> by <span>Lou Jane Temple</span></div></div><div class="list-b-item col-xs-12 col-md-6"><svg enable-background="new 0 0 512 512" viewBox="0 0 512 512" xmlns="http://www.w3.org/2000/svg">
<g>
<path d="m419.17 410.104v62.4h-288.17c-11.87 0-21.5-9.63-21.5-21.5v-19.4c0-11.87 9.63-21.5 21.5-21.5z" fill="#d9ecfd"/>
<path d="m419.17 441.304v31.2h-288.17c-11.87 0-21.5-9.63-21.5-21.5v-9.7z" fill="#c5e2ff"/>
<path d="m132.68 378.104v-370.604h-20.18c-19.33 0-35 15.67-35 35v389.104c0-29.645 24.103-53.64 53.748-53.506z" fill="#db3915"/>
<path d="m132.68 7.5h301.82v370.604h-301.82z" fill="#fc5a36"/><path d="m131 378.104c-29.547 0-53.5 23.953-53.5 53.5v19.396c0 29.547 23.953 53.5 53.5 53.5h303.5v-32h-303.5c-11.874 0-21.5-9.626-21.5-21.5v-19.396c0-11.874 9.626-21.5 21.5-21.5h303.5v-32z" fill="#a42b0f"/>
<path d="m193.467 63.104h180.382v80.72h-180.382z" fill="#ffc85e"/>
<g>
<path d="m434.5 0h-322c-23.435 0-42.5 19.059-42.5 42.485v408.515c0 33.635 27.364 61 61 61h303.5c4.143 0 7.5-3.358 7.5-7.5v-32c0-4.142-3.357-7.5-7.5-7.5h-7.83v-47.396h7.83c4.143 0 7.5-3.358 7.5-7.5v-402.604c0-4.142-3.358-7.5-7.5-7.5zm-349.5 42.485c0-15.155 12.337-27.485 27.5-27.485h12.68v263.534c0 4.142 3.357 7.5 7.5 7.5s7.5-3.358 7.5-7.5v-263.534h286.82v355.604h-286.82v-59.38c0-4.142-3.357-7.5-7.5-7.5s-7.5 3.358-7.5 7.5v59.664c-15.988 1.521-30.186 9.242-40.18 20.721zm326.67 391.319h-53.67c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h53.67v16.196h-280.67c-9.167 0-14.875-7.396-14-16.196h208.31c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5h-208.31c-.875-9.45 4.831-16.2 14-16.2h280.67zm15.33-31.2h-296c-15.99 0-29 13.009-29 29v19.396c0 15.991 13.01 29 29 29h296v17h-296c-25.364 0-46-20.636-46-46v-19.396c0-25.364 20.636-46 46-46h296z"/><path d="m193.469 151.324h180.38c4.143 0 7.5-3.358 7.5-7.5v-80.72c0-4.142-3.357-7.5-7.5-7.5h-45.349c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h37.85v65.72h-165.38v-65.72h94.84c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5h-102.34c-4.143 0-7.5 3.358-7.5 7.5v80.72c-.001 4.142 3.357 7.5 7.499 7.5z"/>
<path d="m341.658 241.592h-116c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h116c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5z"/><path d="m341.658 277.409h-116c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h116c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5z"/>
</g>
</g>
</svg><div><a href="/english-books/full-book-the-goblin-corps-read-online">The Goblin Corps</a> by <span>Marmell, Ari</span></div></div><div class="list-b-item col-xs-12 col-md-6"><svg enable-background="new 0 0 512 512" viewBox="0 0 512 512" xmlns="http://www.w3.org/2000/svg">
<g>
<path d="m419.17 410.104v62.4h-288.17c-11.87 0-21.5-9.63-21.5-21.5v-19.4c0-11.87 9.63-21.5 21.5-21.5z" fill="#d9ecfd"/>
<path d="m419.17 441.304v31.2h-288.17c-11.87 0-21.5-9.63-21.5-21.5v-9.7z" fill="#c5e2ff"/>
<path d="m132.68 378.104v-370.604h-20.18c-19.33 0-35 15.67-35 35v389.104c0-29.645 24.103-53.64 53.748-53.506z" fill="#db3915"/>
<path d="m132.68 7.5h301.82v370.604h-301.82z" fill="#fc5a36"/><path d="m131 378.104c-29.547 0-53.5 23.953-53.5 53.5v19.396c0 29.547 23.953 53.5 53.5 53.5h303.5v-32h-303.5c-11.874 0-21.5-9.626-21.5-21.5v-19.396c0-11.874 9.626-21.5 21.5-21.5h303.5v-32z" fill="#a42b0f"/>
<path d="m193.467 63.104h180.382v80.72h-180.382z" fill="#ffc85e"/>
<g>
<path d="m434.5 0h-322c-23.435 0-42.5 19.059-42.5 42.485v408.515c0 33.635 27.364 61 61 61h303.5c4.143 0 7.5-3.358 7.5-7.5v-32c0-4.142-3.357-7.5-7.5-7.5h-7.83v-47.396h7.83c4.143 0 7.5-3.358 7.5-7.5v-402.604c0-4.142-3.358-7.5-7.5-7.5zm-349.5 42.485c0-15.155 12.337-27.485 27.5-27.485h12.68v263.534c0 4.142 3.357 7.5 7.5 7.5s7.5-3.358 7.5-7.5v-263.534h286.82v355.604h-286.82v-59.38c0-4.142-3.357-7.5-7.5-7.5s-7.5 3.358-7.5 7.5v59.664c-15.988 1.521-30.186 9.242-40.18 20.721zm326.67 391.319h-53.67c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h53.67v16.196h-280.67c-9.167 0-14.875-7.396-14-16.196h208.31c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5h-208.31c-.875-9.45 4.831-16.2 14-16.2h280.67zm15.33-31.2h-296c-15.99 0-29 13.009-29 29v19.396c0 15.991 13.01 29 29 29h296v17h-296c-25.364 0-46-20.636-46-46v-19.396c0-25.364 20.636-46 46-46h296z"/><path d="m193.469 151.324h180.38c4.143 0 7.5-3.358 7.5-7.5v-80.72c0-4.142-3.357-7.5-7.5-7.5h-45.349c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h37.85v65.72h-165.38v-65.72h94.84c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5h-102.34c-4.143 0-7.5 3.358-7.5 7.5v80.72c-.001 4.142 3.357 7.5 7.499 7.5z"/>
<path d="m341.658 241.592h-116c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h116c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5z"/><path d="m341.658 277.409h-116c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h116c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5z"/>
</g>
</g>
</svg><div><a href="/english-books/full-book-taming-charlotte-read-online">Taming Charlotte</a> by <span>Linda Lael Miller</span></div></div><div class="list-b-item col-xs-12 col-md-6"><svg enable-background="new 0 0 512 512" viewBox="0 0 512 512" xmlns="http://www.w3.org/2000/svg">
<g>
<path d="m419.17 410.104v62.4h-288.17c-11.87 0-21.5-9.63-21.5-21.5v-19.4c0-11.87 9.63-21.5 21.5-21.5z" fill="#d9ecfd"/>
<path d="m419.17 441.304v31.2h-288.17c-11.87 0-21.5-9.63-21.5-21.5v-9.7z" fill="#c5e2ff"/>
<path d="m132.68 378.104v-370.604h-20.18c-19.33 0-35 15.67-35 35v389.104c0-29.645 24.103-53.64 53.748-53.506z" fill="#db3915"/>
<path d="m132.68 7.5h301.82v370.604h-301.82z" fill="#fc5a36"/><path d="m131 378.104c-29.547 0-53.5 23.953-53.5 53.5v19.396c0 29.547 23.953 53.5 53.5 53.5h303.5v-32h-303.5c-11.874 0-21.5-9.626-21.5-21.5v-19.396c0-11.874 9.626-21.5 21.5-21.5h303.5v-32z" fill="#a42b0f"/>
<path d="m193.467 63.104h180.382v80.72h-180.382z" fill="#ffc85e"/>
<g>
<path d="m434.5 0h-322c-23.435 0-42.5 19.059-42.5 42.485v408.515c0 33.635 27.364 61 61 61h303.5c4.143 0 7.5-3.358 7.5-7.5v-32c0-4.142-3.357-7.5-7.5-7.5h-7.83v-47.396h7.83c4.143 0 7.5-3.358 7.5-7.5v-402.604c0-4.142-3.358-7.5-7.5-7.5zm-349.5 42.485c0-15.155 12.337-27.485 27.5-27.485h12.68v263.534c0 4.142 3.357 7.5 7.5 7.5s7.5-3.358 7.5-7.5v-263.534h286.82v355.604h-286.82v-59.38c0-4.142-3.357-7.5-7.5-7.5s-7.5 3.358-7.5 7.5v59.664c-15.988 1.521-30.186 9.242-40.18 20.721zm326.67 391.319h-53.67c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h53.67v16.196h-280.67c-9.167 0-14.875-7.396-14-16.196h208.31c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5h-208.31c-.875-9.45 4.831-16.2 14-16.2h280.67zm15.33-31.2h-296c-15.99 0-29 13.009-29 29v19.396c0 15.991 13.01 29 29 29h296v17h-296c-25.364 0-46-20.636-46-46v-19.396c0-25.364 20.636-46 46-46h296z"/><path d="m193.469 151.324h180.38c4.143 0 7.5-3.358 7.5-7.5v-80.72c0-4.142-3.357-7.5-7.5-7.5h-45.349c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h37.85v65.72h-165.38v-65.72h94.84c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5h-102.34c-4.143 0-7.5 3.358-7.5 7.5v80.72c-.001 4.142 3.357 7.5 7.499 7.5z"/>
<path d="m341.658 241.592h-116c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h116c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5z"/><path d="m341.658 277.409h-116c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h116c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5z"/>
</g>
</g>
</svg><div><a href="/english-books/full-book-negligee-behavior-read-online">Negligee Behavior</a> by <span>Shelli Stevens</span></div></div><div class="list-b-item col-xs-12 col-md-6"><svg enable-background="new 0 0 512 512" viewBox="0 0 512 512" xmlns="http://www.w3.org/2000/svg">
<g>
<path d="m419.17 410.104v62.4h-288.17c-11.87 0-21.5-9.63-21.5-21.5v-19.4c0-11.87 9.63-21.5 21.5-21.5z" fill="#d9ecfd"/>
<path d="m419.17 441.304v31.2h-288.17c-11.87 0-21.5-9.63-21.5-21.5v-9.7z" fill="#c5e2ff"/>
<path d="m132.68 378.104v-370.604h-20.18c-19.33 0-35 15.67-35 35v389.104c0-29.645 24.103-53.64 53.748-53.506z" fill="#db3915"/>
<path d="m132.68 7.5h301.82v370.604h-301.82z" fill="#fc5a36"/><path d="m131 378.104c-29.547 0-53.5 23.953-53.5 53.5v19.396c0 29.547 23.953 53.5 53.5 53.5h303.5v-32h-303.5c-11.874 0-21.5-9.626-21.5-21.5v-19.396c0-11.874 9.626-21.5 21.5-21.5h303.5v-32z" fill="#a42b0f"/>
<path d="m193.467 63.104h180.382v80.72h-180.382z" fill="#ffc85e"/>
<g>
<path d="m434.5 0h-322c-23.435 0-42.5 19.059-42.5 42.485v408.515c0 33.635 27.364 61 61 61h303.5c4.143 0 7.5-3.358 7.5-7.5v-32c0-4.142-3.357-7.5-7.5-7.5h-7.83v-47.396h7.83c4.143 0 7.5-3.358 7.5-7.5v-402.604c0-4.142-3.358-7.5-7.5-7.5zm-349.5 42.485c0-15.155 12.337-27.485 27.5-27.485h12.68v263.534c0 4.142 3.357 7.5 7.5 7.5s7.5-3.358 7.5-7.5v-263.534h286.82v355.604h-286.82v-59.38c0-4.142-3.357-7.5-7.5-7.5s-7.5 3.358-7.5 7.5v59.664c-15.988 1.521-30.186 9.242-40.18 20.721zm326.67 391.319h-53.67c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h53.67v16.196h-280.67c-9.167 0-14.875-7.396-14-16.196h208.31c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5h-208.31c-.875-9.45 4.831-16.2 14-16.2h280.67zm15.33-31.2h-296c-15.99 0-29 13.009-29 29v19.396c0 15.991 13.01 29 29 29h296v17h-296c-25.364 0-46-20.636-46-46v-19.396c0-25.364 20.636-46 46-46h296z"/><path d="m193.469 151.324h180.38c4.143 0 7.5-3.358 7.5-7.5v-80.72c0-4.142-3.357-7.5-7.5-7.5h-45.349c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h37.85v65.72h-165.38v-65.72h94.84c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5h-102.34c-4.143 0-7.5 3.358-7.5 7.5v80.72c-.001 4.142 3.357 7.5 7.499 7.5z"/>
<path d="m341.658 241.592h-116c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h116c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5z"/><path d="m341.658 277.409h-116c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h116c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5z"/>
</g>
</g>
</svg><div><a href="/english-books/full-book-down-dirty-read-online">Down & Dirty</a> by <span>Madison, Reese</span></div></div><div class="list-b-item col-xs-12 col-md-6"><svg enable-background="new 0 0 512 512" viewBox="0 0 512 512" xmlns="http://www.w3.org/2000/svg">
<g>
<path d="m419.17 410.104v62.4h-288.17c-11.87 0-21.5-9.63-21.5-21.5v-19.4c0-11.87 9.63-21.5 21.5-21.5z" fill="#d9ecfd"/>
<path d="m419.17 441.304v31.2h-288.17c-11.87 0-21.5-9.63-21.5-21.5v-9.7z" fill="#c5e2ff"/>
<path d="m132.68 378.104v-370.604h-20.18c-19.33 0-35 15.67-35 35v389.104c0-29.645 24.103-53.64 53.748-53.506z" fill="#db3915"/>
<path d="m132.68 7.5h301.82v370.604h-301.82z" fill="#fc5a36"/><path d="m131 378.104c-29.547 0-53.5 23.953-53.5 53.5v19.396c0 29.547 23.953 53.5 53.5 53.5h303.5v-32h-303.5c-11.874 0-21.5-9.626-21.5-21.5v-19.396c0-11.874 9.626-21.5 21.5-21.5h303.5v-32z" fill="#a42b0f"/>
<path d="m193.467 63.104h180.382v80.72h-180.382z" fill="#ffc85e"/>
<g>
<path d="m434.5 0h-322c-23.435 0-42.5 19.059-42.5 42.485v408.515c0 33.635 27.364 61 61 61h303.5c4.143 0 7.5-3.358 7.5-7.5v-32c0-4.142-3.357-7.5-7.5-7.5h-7.83v-47.396h7.83c4.143 0 7.5-3.358 7.5-7.5v-402.604c0-4.142-3.358-7.5-7.5-7.5zm-349.5 42.485c0-15.155 12.337-27.485 27.5-27.485h12.68v263.534c0 4.142 3.357 7.5 7.5 7.5s7.5-3.358 7.5-7.5v-263.534h286.82v355.604h-286.82v-59.38c0-4.142-3.357-7.5-7.5-7.5s-7.5 3.358-7.5 7.5v59.664c-15.988 1.521-30.186 9.242-40.18 20.721zm326.67 391.319h-53.67c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h53.67v16.196h-280.67c-9.167 0-14.875-7.396-14-16.196h208.31c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5h-208.31c-.875-9.45 4.831-16.2 14-16.2h280.67zm15.33-31.2h-296c-15.99 0-29 13.009-29 29v19.396c0 15.991 13.01 29 29 29h296v17h-296c-25.364 0-46-20.636-46-46v-19.396c0-25.364 20.636-46 46-46h296z"/><path d="m193.469 151.324h180.38c4.143 0 7.5-3.358 7.5-7.5v-80.72c0-4.142-3.357-7.5-7.5-7.5h-45.349c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h37.85v65.72h-165.38v-65.72h94.84c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5h-102.34c-4.143 0-7.5 3.358-7.5 7.5v80.72c-.001 4.142 3.357 7.5 7.499 7.5z"/>
<path d="m341.658 241.592h-116c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h116c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5z"/><path d="m341.658 277.409h-116c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h116c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5z"/>
</g>
</g>
</svg><div><a href="/english-books/full-book-black-beauty-read-online">Black Beauty</a> by <span>Anna Sewell</span></div></div><div class="list-b-item col-xs-12 col-md-6"><svg enable-background="new 0 0 512 512" viewBox="0 0 512 512" xmlns="http://www.w3.org/2000/svg">
<g>
<path d="m419.17 410.104v62.4h-288.17c-11.87 0-21.5-9.63-21.5-21.5v-19.4c0-11.87 9.63-21.5 21.5-21.5z" fill="#d9ecfd"/>
<path d="m419.17 441.304v31.2h-288.17c-11.87 0-21.5-9.63-21.5-21.5v-9.7z" fill="#c5e2ff"/>
<path d="m132.68 378.104v-370.604h-20.18c-19.33 0-35 15.67-35 35v389.104c0-29.645 24.103-53.64 53.748-53.506z" fill="#db3915"/>
<path d="m132.68 7.5h301.82v370.604h-301.82z" fill="#fc5a36"/><path d="m131 378.104c-29.547 0-53.5 23.953-53.5 53.5v19.396c0 29.547 23.953 53.5 53.5 53.5h303.5v-32h-303.5c-11.874 0-21.5-9.626-21.5-21.5v-19.396c0-11.874 9.626-21.5 21.5-21.5h303.5v-32z" fill="#a42b0f"/>
<path d="m193.467 63.104h180.382v80.72h-180.382z" fill="#ffc85e"/>
<g>
<path d="m434.5 0h-322c-23.435 0-42.5 19.059-42.5 42.485v408.515c0 33.635 27.364 61 61 61h303.5c4.143 0 7.5-3.358 7.5-7.5v-32c0-4.142-3.357-7.5-7.5-7.5h-7.83v-47.396h7.83c4.143 0 7.5-3.358 7.5-7.5v-402.604c0-4.142-3.358-7.5-7.5-7.5zm-349.5 42.485c0-15.155 12.337-27.485 27.5-27.485h12.68v263.534c0 4.142 3.357 7.5 7.5 7.5s7.5-3.358 7.5-7.5v-263.534h286.82v355.604h-286.82v-59.38c0-4.142-3.357-7.5-7.5-7.5s-7.5 3.358-7.5 7.5v59.664c-15.988 1.521-30.186 9.242-40.18 20.721zm326.67 391.319h-53.67c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h53.67v16.196h-280.67c-9.167 0-14.875-7.396-14-16.196h208.31c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5h-208.31c-.875-9.45 4.831-16.2 14-16.2h280.67zm15.33-31.2h-296c-15.99 0-29 13.009-29 29v19.396c0 15.991 13.01 29 29 29h296v17h-296c-25.364 0-46-20.636-46-46v-19.396c0-25.364 20.636-46 46-46h296z"/><path d="m193.469 151.324h180.38c4.143 0 7.5-3.358 7.5-7.5v-80.72c0-4.142-3.357-7.5-7.5-7.5h-45.349c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h37.85v65.72h-165.38v-65.72h94.84c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5h-102.34c-4.143 0-7.5 3.358-7.5 7.5v80.72c-.001 4.142 3.357 7.5 7.499 7.5z"/>
<path d="m341.658 241.592h-116c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h116c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5z"/><path d="m341.658 277.409h-116c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h116c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5z"/>
</g>
</g>
</svg><div><a href="/english-books/full-book-blind-man-with-a-pistol-read-online">Blind Man With a Pistol</a> by <span>Chester Himes</span></div></div><div class="list-b-item col-xs-12 col-md-6"><svg enable-background="new 0 0 512 512" viewBox="0 0 512 512" xmlns="http://www.w3.org/2000/svg">
<g>
<path d="m419.17 410.104v62.4h-288.17c-11.87 0-21.5-9.63-21.5-21.5v-19.4c0-11.87 9.63-21.5 21.5-21.5z" fill="#d9ecfd"/>
<path d="m419.17 441.304v31.2h-288.17c-11.87 0-21.5-9.63-21.5-21.5v-9.7z" fill="#c5e2ff"/>
<path d="m132.68 378.104v-370.604h-20.18c-19.33 0-35 15.67-35 35v389.104c0-29.645 24.103-53.64 53.748-53.506z" fill="#db3915"/>
<path d="m132.68 7.5h301.82v370.604h-301.82z" fill="#fc5a36"/><path d="m131 378.104c-29.547 0-53.5 23.953-53.5 53.5v19.396c0 29.547 23.953 53.5 53.5 53.5h303.5v-32h-303.5c-11.874 0-21.5-9.626-21.5-21.5v-19.396c0-11.874 9.626-21.5 21.5-21.5h303.5v-32z" fill="#a42b0f"/>
<path d="m193.467 63.104h180.382v80.72h-180.382z" fill="#ffc85e"/>
<g>
<path d="m434.5 0h-322c-23.435 0-42.5 19.059-42.5 42.485v408.515c0 33.635 27.364 61 61 61h303.5c4.143 0 7.5-3.358 7.5-7.5v-32c0-4.142-3.357-7.5-7.5-7.5h-7.83v-47.396h7.83c4.143 0 7.5-3.358 7.5-7.5v-402.604c0-4.142-3.358-7.5-7.5-7.5zm-349.5 42.485c0-15.155 12.337-27.485 27.5-27.485h12.68v263.534c0 4.142 3.357 7.5 7.5 7.5s7.5-3.358 7.5-7.5v-263.534h286.82v355.604h-286.82v-59.38c0-4.142-3.357-7.5-7.5-7.5s-7.5 3.358-7.5 7.5v59.664c-15.988 1.521-30.186 9.242-40.18 20.721zm326.67 391.319h-53.67c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h53.67v16.196h-280.67c-9.167 0-14.875-7.396-14-16.196h208.31c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5h-208.31c-.875-9.45 4.831-16.2 14-16.2h280.67zm15.33-31.2h-296c-15.99 0-29 13.009-29 29v19.396c0 15.991 13.01 29 29 29h296v17h-296c-25.364 0-46-20.636-46-46v-19.396c0-25.364 20.636-46 46-46h296z"/><path d="m193.469 151.324h180.38c4.143 0 7.5-3.358 7.5-7.5v-80.72c0-4.142-3.357-7.5-7.5-7.5h-45.349c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h37.85v65.72h-165.38v-65.72h94.84c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5h-102.34c-4.143 0-7.5 3.358-7.5 7.5v80.72c-.001 4.142 3.357 7.5 7.499 7.5z"/>
<path d="m341.658 241.592h-116c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h116c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5z"/><path d="m341.658 277.409h-116c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h116c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5z"/>
</g>
</g>
</svg><div><a href="/english-books/full-book-fall-roam-series-book-two-read-online">Fall (Roam Series, Book Two)</a> by <span>Stedronsky, Kimberly</span></div></div><div class="list-b-item col-xs-12 col-md-6"><svg enable-background="new 0 0 512 512" viewBox="0 0 512 512" xmlns="http://www.w3.org/2000/svg">
<g>
<path d="m419.17 410.104v62.4h-288.17c-11.87 0-21.5-9.63-21.5-21.5v-19.4c0-11.87 9.63-21.5 21.5-21.5z" fill="#d9ecfd"/>
<path d="m419.17 441.304v31.2h-288.17c-11.87 0-21.5-9.63-21.5-21.5v-9.7z" fill="#c5e2ff"/>
<path d="m132.68 378.104v-370.604h-20.18c-19.33 0-35 15.67-35 35v389.104c0-29.645 24.103-53.64 53.748-53.506z" fill="#db3915"/>
<path d="m132.68 7.5h301.82v370.604h-301.82z" fill="#fc5a36"/><path d="m131 378.104c-29.547 0-53.5 23.953-53.5 53.5v19.396c0 29.547 23.953 53.5 53.5 53.5h303.5v-32h-303.5c-11.874 0-21.5-9.626-21.5-21.5v-19.396c0-11.874 9.626-21.5 21.5-21.5h303.5v-32z" fill="#a42b0f"/>
<path d="m193.467 63.104h180.382v80.72h-180.382z" fill="#ffc85e"/>
<g>
<path d="m434.5 0h-322c-23.435 0-42.5 19.059-42.5 42.485v408.515c0 33.635 27.364 61 61 61h303.5c4.143 0 7.5-3.358 7.5-7.5v-32c0-4.142-3.357-7.5-7.5-7.5h-7.83v-47.396h7.83c4.143 0 7.5-3.358 7.5-7.5v-402.604c0-4.142-3.358-7.5-7.5-7.5zm-349.5 42.485c0-15.155 12.337-27.485 27.5-27.485h12.68v263.534c0 4.142 3.357 7.5 7.5 7.5s7.5-3.358 7.5-7.5v-263.534h286.82v355.604h-286.82v-59.38c0-4.142-3.357-7.5-7.5-7.5s-7.5 3.358-7.5 7.5v59.664c-15.988 1.521-30.186 9.242-40.18 20.721zm326.67 391.319h-53.67c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h53.67v16.196h-280.67c-9.167 0-14.875-7.396-14-16.196h208.31c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5h-208.31c-.875-9.45 4.831-16.2 14-16.2h280.67zm15.33-31.2h-296c-15.99 0-29 13.009-29 29v19.396c0 15.991 13.01 29 29 29h296v17h-296c-25.364 0-46-20.636-46-46v-19.396c0-25.364 20.636-46 46-46h296z"/><path d="m193.469 151.324h180.38c4.143 0 7.5-3.358 7.5-7.5v-80.72c0-4.142-3.357-7.5-7.5-7.5h-45.349c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h37.85v65.72h-165.38v-65.72h94.84c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5h-102.34c-4.143 0-7.5 3.358-7.5 7.5v80.72c-.001 4.142 3.357 7.5 7.499 7.5z"/>
<path d="m341.658 241.592h-116c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h116c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5z"/><path d="m341.658 277.409h-116c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h116c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5z"/>
</g>
</g>
</svg><div><a href="/english-books/full-book-the-mogul-read-online">The Mogul</a> by <span>Marquis, Michelle</span></div></div><div class="list-b-item col-xs-12 col-md-6"><svg enable-background="new 0 0 512 512" viewBox="0 0 512 512" xmlns="http://www.w3.org/2000/svg">
<g>
<path d="m419.17 410.104v62.4h-288.17c-11.87 0-21.5-9.63-21.5-21.5v-19.4c0-11.87 9.63-21.5 21.5-21.5z" fill="#d9ecfd"/>
<path d="m419.17 441.304v31.2h-288.17c-11.87 0-21.5-9.63-21.5-21.5v-9.7z" fill="#c5e2ff"/>
<path d="m132.68 378.104v-370.604h-20.18c-19.33 0-35 15.67-35 35v389.104c0-29.645 24.103-53.64 53.748-53.506z" fill="#db3915"/>
<path d="m132.68 7.5h301.82v370.604h-301.82z" fill="#fc5a36"/><path d="m131 378.104c-29.547 0-53.5 23.953-53.5 53.5v19.396c0 29.547 23.953 53.5 53.5 53.5h303.5v-32h-303.5c-11.874 0-21.5-9.626-21.5-21.5v-19.396c0-11.874 9.626-21.5 21.5-21.5h303.5v-32z" fill="#a42b0f"/>
<path d="m193.467 63.104h180.382v80.72h-180.382z" fill="#ffc85e"/>
<g>
<path d="m434.5 0h-322c-23.435 0-42.5 19.059-42.5 42.485v408.515c0 33.635 27.364 61 61 61h303.5c4.143 0 7.5-3.358 7.5-7.5v-32c0-4.142-3.357-7.5-7.5-7.5h-7.83v-47.396h7.83c4.143 0 7.5-3.358 7.5-7.5v-402.604c0-4.142-3.358-7.5-7.5-7.5zm-349.5 42.485c0-15.155 12.337-27.485 27.5-27.485h12.68v263.534c0 4.142 3.357 7.5 7.5 7.5s7.5-3.358 7.5-7.5v-263.534h286.82v355.604h-286.82v-59.38c0-4.142-3.357-7.5-7.5-7.5s-7.5 3.358-7.5 7.5v59.664c-15.988 1.521-30.186 9.242-40.18 20.721zm326.67 391.319h-53.67c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h53.67v16.196h-280.67c-9.167 0-14.875-7.396-14-16.196h208.31c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5h-208.31c-.875-9.45 4.831-16.2 14-16.2h280.67zm15.33-31.2h-296c-15.99 0-29 13.009-29 29v19.396c0 15.991 13.01 29 29 29h296v17h-296c-25.364 0-46-20.636-46-46v-19.396c0-25.364 20.636-46 46-46h296z"/><path d="m193.469 151.324h180.38c4.143 0 7.5-3.358 7.5-7.5v-80.72c0-4.142-3.357-7.5-7.5-7.5h-45.349c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h37.85v65.72h-165.38v-65.72h94.84c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5h-102.34c-4.143 0-7.5 3.358-7.5 7.5v80.72c-.001 4.142 3.357 7.5 7.499 7.5z"/>
<path d="m341.658 241.592h-116c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h116c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5z"/><path d="m341.658 277.409h-116c-4.143 0-7.5 3.358-7.5 7.5s3.357 7.5 7.5 7.5h116c4.143 0 7.5-3.358 7.5-7.5s-3.357-7.5-7.5-7.5z"/>
</g>
</g>
</svg><div><a href="/english-books/full-book-the-path-of-peace-the-cremelino-prophecy-book-3-read-online">The Path Of Peace (The Cremelino Prophecy Book 3)</a> by <span>Mike Shelton</span></div></div></div>
<!--er-->
</div>
</div>
<div class="row" style="margin-top: 15px;">
</div>
</div>
</div>
<footer class="footer">
<div class="container">
<p class="pull-left">
© FullEnglishBooks 2015 - 2025 Contact for me fullenglishbooks.com@aol.com </p>
<p class="pull-right">
<!--LiveInternet counter-->
<script type="text/javascript">
document.write("<a href='//www.liveinternet.ru/click' "+
"target=_blank><img src='//counter.yadro.ru/hit?t50.6;r"+
escape(document.referrer)+((typeof(screen)=="undefined")?"":
";s"+screen.width+"*"+screen.height+"*"+(screen.colorDepth?
screen.colorDepth:screen.pixelDepth))+";u"+escape(document.URL)+
";h"+escape(document.title.substring(0,150))+";"+Math.random()+
"' alt='' title='LiveInternet' "+
"border='0' width='31' height='31'><\/a>")
</script>
<!--/LiveInternet-->
</p>
</div>
</footer>
<script src="/assets/ba91f165/jquery.js?v=1529425591"></script>
<script src="/assets/618ab67e/yii.js?v=1529414259"></script>
<script src="/js/site.js?v=1722099411"></script>
<script src="/assets/5e1636ad/js/bootstrap.js?v=1529424553"></script>
</body>
</html>