XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (588 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

- Some accented characters exist in both upper-case and lower-case forms, but the upper-case form is usually written without accents when it appears in running text.
Fortunately, the Unicode consortium has defined a mapping from upper-case to lower-case characters, and the XPath specification refers to this mapping. An outline of the principles can be found in Unicode Technical Report #21 (
http://www.unicode.org/unicode/reports/tr21/
). This material has been merged into Unicode 4.0, but in my view the original technical report is easier to read. The actual character mappings can be extracted from the database of Unicode characters found on the Unicode Web site.
The effect of the function is as follows:
- If the input is an empty sequence, the result is the zero-length string.
- Otherwise, every character in the input string is replaced by its corresponding lower-case character (or sequence of characters) if there is one, or it is included unchanged in the result string if it does not.
The function does not implement case mappings that Unicode defines as being locale-sensitive (such as the Turkish dotless I). A good implementation will support the mappings that are context-sensitive (such as the choice between the two lower-case sigma characters), but it would be unwise to rely on it.
Examples
| Expression | Result |
| lower-case(“Sunday”) | “sunday” |
| lower-case(“2+2”) | “2+2” |
| lower-case(“CÉSAR”) | “césar” |
lower-case(“E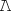 A A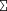 ” ”) | “ϵλλα ” ” |
Usage
With simple ASCII keywords, it's safe to use the
lower-case()
or
upper-case()
functions to do a case-blind comparison, for example:
if (lower-case($param) = “yes”) then …
With a more extensive alphabet, it's better to use a specific collation for this purpose. The reason is that converting two strings to lower case for comparison doesn't always work ( STRASSE
STRASSE will be mapped tostrasse, whileStraßewill be mapped tostraße). Converting both to upper case is better, though there are still a few problems that can crop up.
will be mapped tostrasse, whileStraßewill be mapped tostraße). Converting both to upper case is better, though there are still a few problems that can crop up.
So it's best to use this function only if you genuinely need to convert a string to lower case, not just in order to perform comparisons.