XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (717 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

There's another rule that causes production rules to be numbered manually (using an explicit
num
attribute in the source XML) rather than sequentially in order of appearance. This was done to allow production rules to have numbers such as [28a] and [28b] in revised editions of the specification, allowing existing productions to retain their established numbers.
Such changes are defensible, and one can see why they were made in a overlay rather than in the base stylesheet. Nevertheless, the accumulation of such changes over time can cause a significant change management problem. It doesn't even necessarily prevent the base stylesheet being forked, as we will see in the next section.
Stylesheets for Other Specifications
The stylesheet just presented is used for the XML specification. The stylesheets used for the XPath, XQuery, and XSLT specifications are slightly different, because these documents use additional element types beyond those used in the XML specification. In each case, the XML source document has an internal DTD subset that supplements the base DTD with some additional element types. For example, the XPath
Functions and Operators
document uses special tags to mark up function signatures, and the XSLT document has special tags to mark up the proformas used to summarize the syntax of each XSLT element.
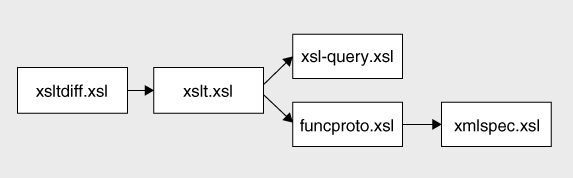
In fact, the XSLT 2.0 specification is formatted using a stack of five stylesheet modules, as described in the following sections. This is a small subset of the total number of stylesheet modules used to produce the XSLT/XQuery family of specifications, which contains no less than 57 separate stylesheet modules (and the number is growing, as the production of errata to the original specs gets under way). The relationship between the five modules used for the XSLT specification is described by the import tree in
Figure 18-5
. The other modules, which we have no space to describe here, handle a wide variety of tasks:
- Many of the documents in the suite have a stylesheet for local customizations. The entire suite includes eight published Recommendations, a couple of specifications that are well advanced to becoming Recommendations, and numerous ancillary documents such as statements of requirements and use cases.
- Formatting of the specialized mathematical notation used in the XQuery formal semantics.
- Extraction of the XPath and XQuery specifications from a common base document, which contains markup indicating which parts apply to which language.
- Construction of an index of term definitions and section headings across the whole family of documents, to allow cross-document references to be maintained easily.
- Stylesheets to automate the comparison of document versions to create change markup.
- Stylesheets to maintain a common bibliography across the full range of documents, which is subsetted to form the reference section in each separate specification.
This collection of 57 modules doesn't even include the complex suite of XSLT stylesheets used to maintain the XQuery grammar: an XML definition of this grammar is used both to generate the production rules that appear in the various specifications and to construct the W3C reference parser (see
www.w3.org/2005/qt-applets/xqueryApplet.html
).
So, we will concentrate here on the production of the XSLT specification.
XSLT.xsl
I developed most of this stylesheet module myself in my role as editor of the XSLT 2.0 specification (some parts were inherited from a similar stylesheet produced by James Clark). It refines the features available from the base stylesheet in three main ways:
- It handles additional markup that is special to the XSLT specification; for example, the proformas used for showing the structure of XSLT instructions, and the markup used for describing error conditions.
- It refines the presentation used for certain constructs, where the default presentation used in the base stylesheet didn't work well for this document. For example, the number of cross-references to other sections of the specification is so great that using a bold font for these became very distracting for the reader, so they were changed to use a normal font. Clearly, such changes need to be made with great discretion, but this is not the right place to discuss typography or editorial policy issues.
- It automates certain things that were not automated by the base stylesheets. For example, it provides an automatically generated glossary, and indexes of error conditions and outstanding issues; it also automates some of the generation of front material and hyperlinks.
In some cases, these changes have had cascading effects. For example, the fact that some sections of the specification are automatically generated means that the stylesheet (in places) operates in two phases. The issues list that appears in earlier working drafts is generated as a temporary document using the markup from the
xmlspec
vocabulary, and this is then rendered into HTML by applying the standard template rules. Unfortunately, certain things break when this is done; for example, the standard
key()
function assumes that both source and target are in the same tree. So, the
xslt.xsl
stylesheet contains a copy of the entire
This is far from ideal, of course. It is always better to get the base stylesheet changed rather than forking the code, but this always takes time and is not possible when timescales are tight. It can then easily happen that differences between versions of the same template gradually accumulate, and it takes constant vigilance to prevent structural decay. This is not really any different, of course, from any other software endeavor.
The
xslt.xsl
stylesheet imports two other stylesheet modules,
funcproto.xsl
and
xsl-query.xsl
.
XSLTdiff.xsl
This is a fork of the
diffspec.xsl
stylesheet described earlier in the chapter. It contains some refinements that were necessary (such as importing
xslt.xsl
instead of
xmlspec.xsl
) and other changes that the editor (that's me) found useful to give extra control, for example labeling of changes with the draft in which they were introduced, thus allowing any two versions of the spec to be differenced. It also handles change marking of some of the features that are unique to the XSLT specification.
This is actually the only stylesheet module that uses XSLT 2.0—a natural consequence of the fact that while the specification was being drafted, the editor was one of the few people with access to an XSLT 2.0 processor. There are only a couple of XSLT 2.0 features used:
- Successive drafts were labelled A, B, C, . . . Z, ZA, ZB, so that the change marking code could detect all changes made since a particular draft with a simple string comparison. String ordering comparisons are not possible in XSLT 1.0 except by the cumbersome device of sorting.
- Some of the template rules take advantage of the ability in XSLT 2.0 to refer to global variables within a match pattern. Because change marking may be switched on or off by setting a global parameter, a template rule can be made conditional by using a pattern such as
funcproto.xsl
This stylesheet module does a well-defined job: it formats the function signatures used in the XPath
Functions and Operators
specification and also in the XSLT specification. As with the XML production rules, these function signatures use a highly structured form of markup that is completely independent of the final presentation. For example, here is the function signature for the
format-date()
function:
returnEmptyOk=“yes”>
I would recommend taking a look at this stylesheet to see how it works (it's available in the downloads for this chapter). There are some interesting features, such as the use of a heuristic calculation that attempts to decide whether to use a single-line format for the function signature, or a multiline format. But I won't include any details here.
xsl-query.xsl
This stylesheet provides a customization of the
xmlspec.xsl
stylesheet that is used by all the specifications in the XSLT/XPath/XQuery family. It provides facilities to support fine-grained cross- references between the different specifications in this family, and to generate appendices such as error listings and glossaries.
Some of these facilities were introduced first in the XSLT specification, and were then adapted for use in other specifications; in some cases, the XSLT specification has changed to use the common capabilities, in other cases it has not. As with any sizable editorial operation, standards and processes are constantly in flux, and at any given point in time, there will be inconsistencies and overlaps. The fact that these exist in this family of stylesheets should be taken as positive evidence that the modular structure of the XSLT language can actually support this kind of change, which can never be synchronized totally across the whole organization. Changes are inevitably piloted in one area, then adopted and adapted in another, and at any one time the overall picture may appear slightly chaotic.
xmlspec.xsl
In theory, the
xmlspec.xsl
stylesheet module used at the base of the import tree for formatting the XSLT specification should be the same as the
xmlspec.xsl
described earlier in this chapter. Unfortunately, though, they aren't quite the same. There's no major difference—apart from the fact that XSLT is using the HTML version of the stylesheet rather than the XHTML version, the only differences are a few enhancements to the base stylesheet that haven't yet been migrated across. But change management is an issue here just as with any other software; and in some ways it's more difficult to maintain change control, because the code is so easy to tweak.
Summary
The case study presented in this chapter was of a real family of stylesheets, used for a real application, and not just developed for teaching purposes. It's perhaps slightly atypical in that much of it was written by XML and XSLT experts who developed the languages while they used them. However, it shares with many other projects the fact that the stylesheets were developed over a period of time by different individuals, that they were often working under time pressure, and that they had different coding styles. So, it's probably not that dissimilar from many other stylesheets used in document-formatting applications.
The phrase “document formatting” is crucial. The main tasks performed in this stylesheet are applying HTML display styles to different elements, generating hyperlinks, and formatting tables. These are all tasks that lend themselves to using the
rule-based
design pattern.
I think there are three main messages to come out of this study:
- Within an application that is doing very simple document formatting 90 percent of the time, it is possible to get benefits by using structured data for small parts of the information that have rich semantics—in this case, examples are the markup used for syntax productions, function prototypes, issue tracking, and error listings. The availability of XSLT really does enable you to use XML to represent the semantics of the data, uninfluenced by the way it is to appear on screen.
- Although most of this can be done reasonably easily using XSLT 1.0 facilities, as soon as the data gets complex, XSLT 2.0 features start to make a big impact.
- Within any complex publishing operation that's producing a large suite of documents, the key to success is not so much the detail of how individual stylesheets are coded but rather the overall structure of how many stylesheet modules there are, how they relate to each other, and how change is controlled.
The case study in the next chapter will be a very different kind of application—one that uses a highly structured data and displays it in a very different form from the way it arrives in the source document.
Chapter 19
Case Study: A Family Tree
This chapter presents our second case study. Whereas the XML in the previous example fell firmly into the category of narrative (or document-oriented) XML, this chapter deals largely with data. However, as with many data-oriented XML applications, it is not rigid tabular data; rather, it is data with a very flexible structure with many complex linkages and with many fields allowed to repeat an arbitrary number of times. The data can also include structured text (document-oriented XML) in some of its elements.
The chosen application is to display a family tree, and the sample data we will use represents a small selection of information about the family of John F. Kennedy, president of the United States.
Because genealogy is for most people a hobby rather than a business, you may feel this example is a little frivolous. I think it would be a mistake to dismiss it that way, for several reasons:
- Genealogy is one of the most popular ways of using the Web for millions of people. Collaborative Internet-based genealogy in particular is rapidly growing, as witness the popularity of software such as PhpGedView (
phpgedview.net
) and can be seen as a classic example of the phenomenon sometimes called “Web 2.0”. Catering to the information needs of consumers is a very serious business indeed, and whether consumers are interested in playing games, watching sport, making travel plans, or researching their family trees, the Web is in the business of helping them to do so. Genealogy is also one of the few areas where Web sites have built financial success by asking consumers to pay for content. - Genealogical information presents some complex challenges in terms of managing richly structured data, and these same problems arise in many other disciplines such as geographic information systems, criminal investigation, epidemiology, and molecular biology. Data that fits neatly into rows and columns, to my mind, isn't interesting enough to be worth studying, and what's more, it's likely that the only reason it fits neatly into rows and columns is that a lot of important information has been thrown away in order to achieve that fit. With XML, we can do better.
- To write the application shown in this chapter, we have to tackle the problems of converting from non-XML legacy data formats to XML formats, and from one XML data model to another, which are absolutely typical of the data conversion problems encountered in every real-world application.
I could have used an example with invoices and requisitions and purchase orders. I believe that the techniques used in this worked example are equally applicable to many practical commercial problems, but that you will find a little excursion into the world of genealogy a pleasant relief from the day job.
Modeling a Family Tree
Genealogical data is complex for two main reasons:
- We want to record all the facts that we know about our ancestors, and many of these facts will not fit into a rigidly predefined schema. For those facts that follow a regular pattern, however, we want to use a structured representation so that we can analyze the data.
- The information we have is never complete, and it is never 100% accurate. Genealogy is always work-in-progress, and the information we need to manage includes everything from original source documents and oral evidence to the conjectures of other genealogists (not to mention Aunt Maud) whom we may or may not trust. In this respect it is similar to other investigative applications like crime detection and medical diagnosis.
One caveat before we start. Throughout this book I have been talking about tree models of XML, and I have been using words like parent and child, ancestor and descendant, in the context of these data trees. Don't imagine, though, that we can use this tree structure to represent a family tree directly. In fact, a family tree is not really a tree at all, because most children in real life have two parents, unlike XML elements where one parent is considered sufficient.
The structure of the family tree is quite different from the document tree used to represent it. And in this chapter, words like parent and child have their everyday meaning!
The GEDCOM Data Model
The established standard for representing genealogical data is known as GEDCOM, and data in this format is routinely exchanged between software packages and posted on the Internet. I will show some examples of this format later in the chapter.
Adoption of XML in genealogy has been slow, despite the obvious potential. In earlier editions of this book, I devised my own XML representation. However, in December 2002 the LDS Church (which maintains the GEDCOM specification) published a draft specification of GEDCOM XML, version 6.0. Although this draft hasn't been followed up by a final specification and is not yet widely supported by software products, it is this vocabulary that I shall use in this chapter. The specification is available at
http://www.familysearch.org/GEDCOM/GedXML60.pdf
. Further information about the use of XML in genealogy can be found on the XML Cover Pages at
http://xml.coverpages.org/genealogy.html
.
The GEDCOM XML spec includes a DTD rather than a schema. Several versions of this DTD are referenced from the XML Cover Pages; I have taken the one prepared by Lee Brown and have copied it for convenience as file
gedXML.dtd
in the download file for this chapter.
In defining version 6 of GEDCOM, the designers decided to do two things at the same time: to change the syntax of the data representation, so that it used XML instead of GEDCOM's earlier proprietary tagging syntax, and to change the data model, to fix numerous problems that had inhibited accurate data exchange between different software packages for years.
The three main objects in the new model are
individuals
,
events
, and
families
.
It might seem obvious what an individual is, but serious genealogists know that identifying individuals is actually one of the biggest problems: Is the Henry Kay who was born in Stannington in 1833 the same individual as the Henry Kay who married Emma Barber in Rotherham in 1855? (If you happen to know, please tell me.)
For this reason, the data is actually centered around the concept of an
event
. The main events of interest are births, marriages, and deaths, but there are many others; for example, emigration, writing a will, and a mention in a published book can all be treated as events. In earlier times, births and deaths were not systematically recorded, but baptisms and burials were, so these events assume a special importance. Events have a number of attributes:
- The date of the event
: There are many complexities involved in recording historical dates, due to the use of different calendars, partial legibility, and varying precision. - The place of the event
: Again, this is not a simple data element. Places change their names over time, and place names are themselves structured information, with a structure that varies from one country to another. (Some software packages like to pretend that every event happens in a “city”, but they are wrong. Even in the limited data used in this chapter, we have two deaths that occurred in the air, over international waters). - The participants in the event
: There may be any number of participants, and each has a role. For example, if the event is a marriage, then everyone who is known to have been present at the wedding can be regarded as a participant. Obvious roles include that of the bride, the groom, and the witnesses, but many records also provide the names of the father of the bride and the father of the groom, and this information has obvious genealogical significance. Moreover, it's important to record it even if it seems redundant, because it may help to resolve questions that are raised later when conflicting evidence emerges. - Evidence for the event
: This includes references to source information recording the event, and may include copies or transcripts of original documents.
Here is an example of an event from the Kennedy data set. I have included some additional information beyond that in the data we are using, to show some of the additional possibilities in the data model.
This event is the marriage of John F. Kennedy to Jacqueline Lee Bouvier. Of course, the event information only makes sense by following the links to the participating individuals.
The properties of an individual include:
- Name (another potentially very complex data element, given the variety of conventions used in different places at different times). This element can be repeated, because a person can have different names at different times.
- Gender (male, female, or unknown; the model does not recognize this as an attribute that can change over time).
- Personal information: an open-ended set of information items about the person, each tagged with the type of information, optional date and place fields, and the actual information content. Certain types of personal information such as occupation, nationality, religion, and education are specifically recognized in the specification, but the list is completely open-ended.
The third fundamental object in the GEDCOM model is the family. A family is defined as a social group in which one individual takes the role of husband/father, another takes the role of wife/mother, and the others take the role of children. Any of the individuals may be absent or unknown, and the model is flexible as to the exact nature of the relationships: the parents, for example, are not necessarily married, and the children are not necessarily the biological children of the parents. An individual may be a member of several families, either consecutively or concurrently (membership in a family is not governed by dates).
There are actually three ways of representing relationships in the model. One way is through families, as described above. The second is through events: a birth event may record the person being born, the mother, and the father as participants in the event with corresponding roles. For certain key events, there are fixed roles with defined names (
principal, mother
, and
father
in this case). The third way is to use the properties of an individual: one can record as a property of an individual, for example, that his godfather was Winston Churchill. These variations are provided to reflect the variety of ways in which genealogical data becomes available. The genealogical research process starts by collecting raw data, which is usually data either about events or about individuals, and gradually builds from this to draw inferences about the identity of individuals and the way in which they relate to each other in families. The model has the crucial property that it allows imprecise information to be captured; for example, you can record that A and B were cousins without knowing precisely how they were related, and you can record that someone was the second of five children without knowing who the other children were. The ability to record this kind of information makes XML ideally suited to genealogical data management.
Apart from individual, event, and family, there are five other top-level object types in the GEDCOM model, but we won't be dealing with them in this chapter:
- A
group
is a collection of individuals related in some arbitrary way (for example, the individuals who were staying at a particular address on the night of a census). - A
contact
is typically another genealogist, for example one who collaborates in the research on the individuals in this data set. - A
source
is a document from which information has been obtained, such as a parish register or a will. It might also be a secondary source such as a published obituary. - A
repository
is a place where source documents may be found, for example a library or a Web site, or the bottom drawer of your filing cabinet. - An
LDS Ordinance
is an event of specific interest to the Church of Jesus Christ of Latter-day Saints (often called the Mormons), which is the organization that created the GEDCOM standard.
I'm not going to spend time discussing whether this is the perfect way of representing genealogical information. Many people have criticized the data model, either on technical grounds or from the point of view of political correctness. The new model in version 6 corrects many of the faults of the established version, without departing from it as radically as some people would have liked.
I would have liked to see some further changes—for example, some explicit ability to associate personal names with events rather than with individuals (I have an ancestor who is named Ada on her birth certificate but who was baptized as Edith). But with luck, the amount of change in the GEDCOM model is enough to fix the worst faults, but not so extensive that software products will need wholesale rewriting before they can support it.
Creating a Schema for GEDCOM 6.0
Because genealogical data is a perfect example of semi-structured data (it includes the full spectrum from raw images and sound recordings, through transcribed text, to fully structured and hyperlinked data) it is an ideal candidate for using an XML Schema to drive validation of the data and to produce XSLT stylesheets that are schema-aware. I have therefore produced a schema for GEDCOM 6.0, which I introduce in the next section.