XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (85 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

Enough of this introduction to type systems in programming languages: let's get down to details.
Changes in 2.0
XPath 1.0 only supported three atomic types: boolean, double-precision floating point, and string. This has been generalized to allow all the types defined in XML Schema.
XPath 1.0 supported node-sets (unordered collections of nodes, with no duplicates). XPath 2.0 generalizes this to support sequences, which are ordered and may contain duplicates, and which may contain atomic values as well as nodes.
The thinking on types has changed considerably between XPath 1.0 and XPath 2.0. In 1.0, there were very few types, and very little type checking. Almost all operations were permitted, and runtime errors were very rare. That sounds good on the surface, but what it actually means is that if you make a mistake, you don't get an error message—you just get the wrong answer back (or no answer at all, which can be even more bewildering). This approach to language design generally goes under the name
dynamic typing
or
weak typing
, and it is found most often in scripting languages such as JavaScript and Perl. XPath 2.0 has made a significant shift toward the other approach to language design, based on
static typing
or
strong typing
, which is more characteristic of compiled languages such as C or Java. It has to be said that not everyone is happy with the change, though there are good reasons for it, essentially the fact that XSLT (and its cousin, XQuery) are starting to be used to tackle much bigger problems where a more robust engineering approach is needed.
Actually, the really innovative thing about XPath 2.0 is that it tries to accommodate multiple approaches to typing within a single language. Because XML itself is used to handle a very wide spectrum of different kinds of document, from the very rigidly structured to the very flexible, XPath 2.0 has been designed to accommodate both very flexible and dynamic approaches, where you have no idea what the data is going to look like in advance, to highly structured queries where the structure of the data is regular and predictable and the expression can be optimized to take advantage of the fact. That's the theory, anyway; in practice, as one might expect, there are a few wrinkles.
Sequences
Sometimes object programming languages introduce their data model with the phrase “everything is an object”. In the XPath 2.0 data model, the equivalent statement is that every value is a
sequence
.
By
value
, we mean anything that can be the result of an expression or an operand of an expression. In XPath 2.0, the value of every expression is a sequence of zero or more items. Of course XPath, like other languages, can use atomic values such as integers and booleans. But in XPath, an atomic value is just a special case of a sequence: it is a sequence of length one.
The items in a sequence are ordered. This means that the sequence (1, 2, 3) is different from the sequence (2, 3, 1). The XPath 2.0 data model does not have any direct means of representing unordered collections. Instead, where ordering is unimportant, it makes this part of the definition of an operator on sequences: for example, the
distinct-values()
function returns a number of values with no defined ordering, and with duplicates disallowed, but the result is still presented as a sequence. The ordering might sometimes be arbitrary and left to the implementation to determine, but there is always an ordering.
The items in a sequence are always numbered starting at 1. The number of items in a sequence (and therefore, the number assigned to the last item in the sequence) can be obtained using the
count()
function. (The functions available in XPath 2.0, such as
count()
and
distinct-values()
, are listed in Chapter 13.)
Sequences have no properties other than the items they contain. Two sequences that contain the same items are indistinguishable, so there is no concept of a sequence having an identity separate from its contents.
A sequence can be empty. Because two sequences that contain the same items are indistinguishable, there is no difference between one empty sequence and another, and so we often refer to
the
empty sequence rather than to
an
empty sequence. An empty sequence, as we shall see, is often used to represent absent data in a similar way to nulls in SQL.
The items in a sequence are either
atomic values
, or
nodes
. An atomic value is a value such as an integer, a string, a boolean, or a date. Nodes have already been described in Chapter 2. We will examine atomic values in much greater detail later in this chapter. Most sequences either consist entirely of nodes, or entirely of atomic values, but it's quite legitimate (and occasionally useful) to have a sequence that consists, say, of two strings, an integer, and three element nodes.
The relationships between sequences, items, atomic values and nodes are summarized in the simple UML diagram in
Figure 5-1
.
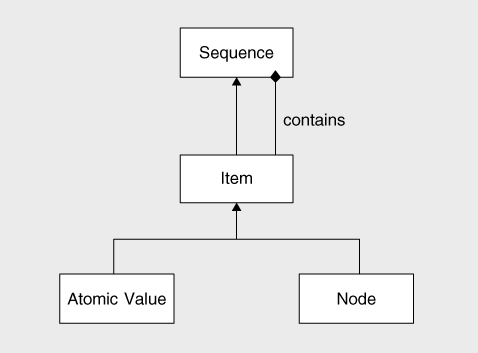
This shows that:
- A sequence contains zero or more items
- An item is itself a sequence
- An atomic value is an item
- A node is an item
Although we talk about a sequence containing nodes, this doesn't mean that a node can only be in one sequence. Far from it. It might be less confusing if we spoke of the sequence containing references to nodes rather than containing the nodes themselves, or if we used a verb other than “contains”—but sadly, we don't.
A sequence can only contain individual items; it cannot contain or reference other sequences. This is an aspect of the data model that some people find surprising, but there are good reasons for it. The usual explanations given are:
- Sequences in the XDM model are designed primarily to represent lists as defined in XML Schema. For example, XML Schema allows the value of an attribute to be a list of integers. These lists cannot be nested, so it wouldn't make sense to allow nested lists in XDM either.
- Sequences that contain sequences would allow trees and graphs to be constructed. But these would bear no relationship to the trees used to represent XML documents. In XDM we need a representation of trees that is faithful to XML; we don't need another kind of tree that bears no relationship to the XML model.
The effect of this rule is that if you need a data structure to hold something more complicated than a simple list of items, it's best to represent it as an XML document. (This is easy when you are using XSLT or XQuery, which allow you to construct nodes in new trees at any time. It's less easy in standalone XPath, which is a read-only language.)
The simplest way of writing an XPath expression whose value is a sequence is by using a comma-separated list: for example, 1, 2, 3
1, 2, 3 represents a list containing three integers. In fact, as we will see in Chapter 10, the comma is a binary operator that concatenates two sequences. Remember that a single integer is a sequence. So1, 2concatenates the single-item sequence1and the single-item sequence2to create the two-item sequence1, 2. The expression1, 2, 3is evaluated as(1, 2), 3
represents a list containing three integers. In fact, as we will see in Chapter 10, the comma is a binary operator that concatenates two sequences. Remember that a single integer is a sequence. So1, 2concatenates the single-item sequence1and the single-item sequence2to create the two-item sequence1, 2. The expression1, 2, 3is evaluated as(1, 2), 3