Life's Greatest Secret (22 page)
Read Life's Greatest Secret Online
Authors: Matthew Cobb

Crick did not consciously set out to support the neo-Darwinian position – that would indeed have been dogmatic. Instead he developed his ideas on the basis of the experimental data, which revealed no potential mechanism for information to go from protein to DNA.
26
Crick recalled:
26
Crick recalled:
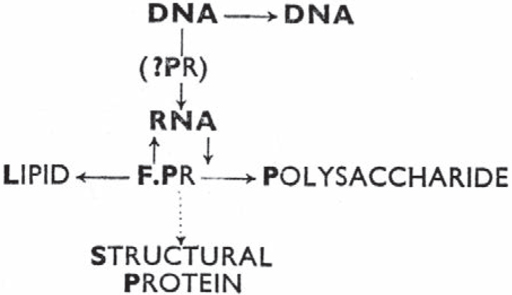
6. Burnet’s view of the pathway from DNA to protein, from Burnet (1956). PR = protein, F.PR = functional proteins, such as enzymes.
Nobody
tried to go from protein sequence back to nucleic acid, because that wasn’t on. You see. But I don’t think it was ever
discussed
.
27
As Crick explained in both his
Scientific American
article and his lecture, he was struck by Macfarlane Burnet’s adoption of a rather different position in
Enzyme, Antigen and Virus.
Burnet later described this as ‘a rather bad over-ambitious book’, primarily because he very soon changed his views on its main subject – the way in which antibodies are created.
28
Whatever the book’s virtues, it contains a diagram outlining his view that may have been the inspiration for Crick’s sketch.
Scientific American
article and his lecture, he was struck by Macfarlane Burnet’s adoption of a rather different position in
Enzyme, Antigen and Virus.
Burnet later described this as ‘a rather bad over-ambitious book’, primarily because he very soon changed his views on its main subject – the way in which antibodies are created.
28
Whatever the book’s virtues, it contains a diagram outlining his view that may have been the inspiration for Crick’s sketch.
Given that Burnet stated that he was trying to apply information theory to cell communication, it is notable that his arrows do not show the flow of information, but instead represent what he called specific pattern (a rather vague concept that seemed to mean something like specificity). In the accompanying text, Burnet described how the system was capable of ‘transferring coded information in pattern on one medium to a different coding of pattern on another medium’.
29
Burnet’s main difference with Crick, apart from the systematic importance he gave to enzymes (given in the diagram as ‘F.PR = functional proteins’), was that the gene product can alter the genetic message, in the shape of the RNA. In Burnet’s schema, information can get from the protein into RNA, and hence into the way in which genetic information is represented. Although Crick implied that Burnet argued that proteins could affect DNA, this was not in fact what Burnet stated. Burnet’s explanation of his hypothesis was complex and was based on his then-current model of how the body is able to generate vast numbers of different molecules that are used in the immune response as a way of differentiating self from non-self. Burnet argued that foreign proteins or antigens prompted the body to produce a specific antibody by becoming incorporated into the RNA; this was the nature of the arrow going from ‘F.PR’ to RNA.
30
Within three years, Burnet had abandoned this view in favour of his new clonal theory of antibody generation; a year after that he won the Nobel Prize in Physiology or Medicine for his work on viruses and the immune response.
29
Burnet’s main difference with Crick, apart from the systematic importance he gave to enzymes (given in the diagram as ‘F.PR = functional proteins’), was that the gene product can alter the genetic message, in the shape of the RNA. In Burnet’s schema, information can get from the protein into RNA, and hence into the way in which genetic information is represented. Although Crick implied that Burnet argued that proteins could affect DNA, this was not in fact what Burnet stated. Burnet’s explanation of his hypothesis was complex and was based on his then-current model of how the body is able to generate vast numbers of different molecules that are used in the immune response as a way of differentiating self from non-self. Burnet argued that foreign proteins or antigens prompted the body to produce a specific antibody by becoming incorporated into the RNA; this was the nature of the arrow going from ‘F.PR’ to RNA.
30
Within three years, Burnet had abandoned this view in favour of his new clonal theory of antibody generation; a year after that he won the Nobel Prize in Physiology or Medicine for his work on viruses and the immune response.
In the 1960s, Crick’s central dogma was rendered truly dogmatic by Jim Watson, who included a simplified version in his textbook
Molecular Biology of the Gene,
converting it to the form first outlined by Boivin in 1949 and Dounce in 1952: DNA → RNA → protein.
31
Crick’s initial view, which allowed for the unlikely possibility of information transfer from RNA to DNA, was largely forgotten. Crick’s dramatic and mistaken use of words ended up undermining his aim – for some scientists, the central dogma became a dogma, and not merely a hypothesis.
32
Molecular Biology of the Gene,
converting it to the form first outlined by Boivin in 1949 and Dounce in 1952: DNA → RNA → protein.
31
Crick’s initial view, which allowed for the unlikely possibility of information transfer from RNA to DNA, was largely forgotten. Crick’s dramatic and mistaken use of words ended up undermining his aim – for some scientists, the central dogma became a dogma, and not merely a hypothesis.
32
*
Like Burnet, Crick was later critical of his own work. In his autobiography, Crick described ‘On protein synthesis’ as ‘a mixture of good and bad ideas, of insight and nonsense’.
33
As with Burnet, Crick’s self-criticism was aimed at those detailed areas of the mechanism that he got wrong. On the big picture, Crick was absolutely right. And in one area, both he and Burnet were positively visionary. Although neither Burnet nor Crick were evolutionary biologists, they each had insights into the way that evolution affects genetic information, insights that are still valid today. In his 1957 talk, Crick pointed to the handful of proteins that had thus far been sequenced in more than one organism and made a leap of the imagination that eventually transformed how we study evolution:
33
As with Burnet, Crick’s self-criticism was aimed at those detailed areas of the mechanism that he got wrong. On the big picture, Crick was absolutely right. And in one area, both he and Burnet were positively visionary. Although neither Burnet nor Crick were evolutionary biologists, they each had insights into the way that evolution affects genetic information, insights that are still valid today. In his 1957 talk, Crick pointed to the handful of proteins that had thus far been sequenced in more than one organism and made a leap of the imagination that eventually transformed how we study evolution:
Biologists should realise that before long we shall have a subject which might be called ‘protein taxonomy’ – the study of the amino acid sequences of the proteins of an organism and the comparison of them between species. It can be argued that these sequences are the most delicate expression possible of the phenotype of an organism and that vast amounts of evolutionary information may be hidden away within them.
34
Crick was right. Today, protein fragments from the depths of time, such as bits of collagen from
Tyrannosaurus rex,
can be used to study evolution.
35
Tyrannosaurus rex,
can be used to study evolution.
35
Burnet’s contribution to evolutionary biology was less dramatic but equally insightful. In the pages of
Enzyme, Antigen and Virus,
Burnet described the Watson–Crick model of the genetic code – that is, of a relation between a sequence of four nucleotide bases in the nucleic acid and the near-infinite structure of proteins – as ‘faintly unsatisfactory’.
36
What exactly was ‘unsatisfactory’ – apart from the fact that the genetic code was still unbroken – Burnet did not explain. Instead he did some quick back-of-the-envelope calculations about the amount of DNA in an average cell and came up with a problem. Assuming that a human cell contained 40,000 genes, each composed of 3,000 bases, that would still account for only 1 per cent of the DNA that was estimated to be present in the nucleus of a human cell; this raised the question of what the other 99 per cent was doing.
37
Although Burnet’s guesstimate that an average gene was 3,000 bases long was entirely gratuitous (genes are in fact often much, much bigger), his question was entirely valid – much of the DNA in our cells seems to be doing nothing. By the 1970s, when it became obvious that this really was a problem, Burnet’s insight had long been forgotten.
Enzyme, Antigen and Virus,
Burnet described the Watson–Crick model of the genetic code – that is, of a relation between a sequence of four nucleotide bases in the nucleic acid and the near-infinite structure of proteins – as ‘faintly unsatisfactory’.
36
What exactly was ‘unsatisfactory’ – apart from the fact that the genetic code was still unbroken – Burnet did not explain. Instead he did some quick back-of-the-envelope calculations about the amount of DNA in an average cell and came up with a problem. Assuming that a human cell contained 40,000 genes, each composed of 3,000 bases, that would still account for only 1 per cent of the DNA that was estimated to be present in the nucleus of a human cell; this raised the question of what the other 99 per cent was doing.
37
Although Burnet’s guesstimate that an average gene was 3,000 bases long was entirely gratuitous (genes are in fact often much, much bigger), his question was entirely valid – much of the DNA in our cells seems to be doing nothing. By the 1970s, when it became obvious that this really was a problem, Burnet’s insight had long been forgotten.
Crick’s 1957 speech and the articles that accompanied it were enormously influential, in terms of both the ideas they contained and the words they used. Crick’s framework – seeing genes and proteins in terms of information flow – rapidly became the accepted way of understanding the fundamental processes of cells. It might be expected that this shift would have been accompanied by a flourishing application of information theory in the realm of molecular biology – Crick’s information could surely be studied using Shannon and Wiener’s equations. In fact, at the same time as Crick came up with the idea of the central dogma, it began to become evident that information theory was not going to transform biology.
*
In 1942, 3,000 people who lived and worked on a plateau near Oak Ridge in the Appalachian Mountains were ordered to leave their homes. Within a year, the US government had built a small city on the site, devoted to the production of weapons-grade uranium and plutonium as part of the drive to build the atomic bomb. Thousands of workers were involved in this top-secret work, which cost more than $1bn to set up. After the war, Oak Ridge National Laboratory focused on the development of nuclear reactors and on the production of radioisotopes for use in medicine and in research, as well as occasional crazy projects such as a plan to build a nuclear-powered aircraft. New groups were set up at the laboratory, including a Biology Division to study the effects of radiation and a Mathematical and Computing Section, armed with the latest von Neumann computers, to analyse the data that the site generated. Researchers at Oak Ridge had a broad range of scientific interests, and in 1950 some of them organised the meeting on the chemistry of nucleic acids at which Chargaff showed that DNA was not a boring molecule.
At the end of October 1956, scientists at the laboratory held a symposium on the links between information theory and biology, following in the footsteps of Henry Quastler’s 1952 meeting. The conference, hosted by the Manhattan Project physicist Hubert Yockey, was entitled ‘A Symposium on Information Theory in Health Physics and Radiobiology’, and half of the talks focused on how radiation and ageing affected biological tissues and processes.
38
Some of the other presentations ambitiously tried to find evidence for negative feedback in liver regeneration, or studied the role of protein synthesis and information transfer in the development of the chick embryo, but none came to any real conclusion. The main issues that were discussed in the autumn Appalachian air related to the application of information theory to the genetic code. Gamow and Yčas were there, although they were the only members of the coding community who attended – none of the experimentalists who were involved in trying to crack the code made the trip.
38
Some of the other presentations ambitiously tried to find evidence for negative feedback in liver regeneration, or studied the role of protein synthesis and information transfer in the development of the chick embryo, but none came to any real conclusion. The main issues that were discussed in the autumn Appalachian air related to the application of information theory to the genetic code. Gamow and Yčas were there, although they were the only members of the coding community who attended – none of the experimentalists who were involved in trying to crack the code made the trip.
Yockey began uncontroversially by outlining what he called the coding chain: protein specificity was encoded by the order of amino acids, which in turn was encoded by the order of base pairs, which in turn implied the existence of a code that translated from four ‘letters’ (A, C, G and T) to twenty ‘words’ (the amino acids). Then, with the confidence of a theoretician unhindered by experimental facts, Yockey suggested that cracking the code was a problem for mathematicians, not biologists:
Thus by following the logical consequences of purely biological, or perhaps biochemical, problems, one is led directly to a problem purely mathematical in character.
39
Yockey claimed that ‘the central ideas of this paper are independent of much of the detail embodied in Watson and Crick’s papers’ – the coding problem had no necessary link with biochemical reality, he seemed to be suggesting. Nonetheless, he boldly claimed that it was possible that ‘the role information theory will play in biology will parallel that played by thermodynamics in physics and chemistry.’
40
40
Gamow and Yčas were less optimistic. Yčas looked at the information content of proteins, treating them as a text and applying cryptographic techniques to work out the genetic code that lay behind it. To Yčas’s dismay, there was no apparent consistency in the organisation and length of protein molecules, and an audacious attempt to predict protein diversity from RNA diversity failed dismally.
41
In a joint paper with Yčas, Gamow summarised the molecular model of gene function that flowed from Watson and Crick’s work, but ultimately could only express his weary conviction that as more protein sequences became known, ‘this problem will be solved in one way or another’. The only way in which Gamow could conceive of cracking the code was by continuing to treat it as a mathematical puzzle that would eventually reveal a solution if probed with sufficient ingenuity.
41
In a joint paper with Yčas, Gamow summarised the molecular model of gene function that flowed from Watson and Crick’s work, but ultimately could only express his weary conviction that as more protein sequences became known, ‘this problem will be solved in one way or another’. The only way in which Gamow could conceive of cracking the code was by continuing to treat it as a mathematical puzzle that would eventually reveal a solution if probed with sufficient ingenuity.
In contrast, the scientists at the meeting who were most directly involved in information theory were beginning to question whether the informational approach to biology was the right one at all. In so doing, they began to undermine some of the main points of Shannon’s original vision. It was widely known that Shannon was not enthusiastic about the application of his ideas to fields other than the strict realm of communication. Henry Quastler, who had organised the 1952 meeting and had been the intellectual driving force behind the biological application of Shannon’s ideas, countered this criticism by showing that information theory was an appropriate tool for biology: biological systems involve control, control depends on communication, and communication depends on information. This neat summary tied in with cybernetics, but brought in another problem: meaning.
The key point in cybernetics was that certain signals – for example negative feedback – had greater significance than others in determining how a system functioned. Meaning had been anathema to Shannon, who had insisted that information had to be considered at a completely abstract level for his theory to exercise its full power. But it seemed that in biological systems it was impossible to avoid meaning. In 1953 this point had been the focus of a highly critical paper presented to a meeting on cybernetics by the philosopher Yehoshuua Bar-Hillel.
42
At the 1956 Oak Ridge meeting, the physicist Leroy Augenstine took up the argument and pointed out that not all ‘bits’ of information were equivalent – their meaning and context had to be taken into account:
42
At the 1956 Oak Ridge meeting, the physicist Leroy Augenstine took up the argument and pointed out that not all ‘bits’ of information were equivalent – their meaning and context had to be taken into account:
It seems very likely that one bit of potential structural information will not always transmit the same amount of information; rather, the efficiency of transmission will depend upon the context within which the performance is measured. … This is somewhat analogous to the relative difficulties of determining whether a symbol is 0 or 1, or to determining whether one should get married or not!
43
To understand messages, information theorists needed more than bits; they had to introduce context and meaning into their calculations. Quastler highlighted the problem by using the example of a conversation between two individuals. At first sight, it might appear that during a conversation, information is transmitted by words. This is undoubtedly the case, but many other factors are involved, such as the selection of particular words from various potential synonyms, the tone of voice, the timing of the utterance, speech volume and so on. Identifying all these levels of potential information seemed impossible. What appears to be a simple example of information transmission is in fact extremely complex. Quastler concluded: ‘In such a situation we have obviously no hope ever to obtain a precise, unequivocal, and incontestable measure of information content.’
44
44
Other books
River of Eden by Mcreynolds, Glenna
Possession by Elana Johnson
Once Upon a Kiss by Tanya Anne Crosby
Quarry's Deal by Max Allan Collins
Solomon's Grave by Keohane, Daniel G.
Contents Under Pressure by Edna Buchanan
Longing by J. D. Landis
Angel Among Us by Katy Munger
The Blind Tiger: An Unusual Paranormal Romance by Dawn Steele
The Fairy-Tale Detectives (The Sisters Grimm, Book 1) by Michael Buckley