Life's Greatest Secret (21 page)
Read Life's Greatest Secret Online
Authors: Matthew Cobb

As Crick outlined in both his symposium talk and in his
Scientific American
article, the direct evidence for the involvement of nucleic acids in protein synthesis came from two recent sources – Ingram’s discovery of the molecular basis of sickle-cell anaemia, and work on the tobacco mosaic virus (TMV), which was now known to use RNA as its genetic material. In 1956, Heinz Fraenkel-Conrat, a biochemist working at Berkeley, had shown that it was possible to separate the RNA and protein components of the TMV and then reassemble them to produce a functional virus. Fraenkel-Conrat then went on to recombine protein from one TMV strain and RNA from another strain; the recombinant strains produced viruses with proteins that were typical of the RNA donor strain and never like those found in the protein donor strain. In his 1957 lecture, Crick described this finding and concluded: ‘the viral RNA appears to carry at least part of the information which determines the composition of the viral protein’.
10
For the first time, Crick spelled out the precise implications of the use of the term information in genetics: ‘By information I mean the specification of the amino acid sequence of the protein.’
11
Scientific American
article, the direct evidence for the involvement of nucleic acids in protein synthesis came from two recent sources – Ingram’s discovery of the molecular basis of sickle-cell anaemia, and work on the tobacco mosaic virus (TMV), which was now known to use RNA as its genetic material. In 1956, Heinz Fraenkel-Conrat, a biochemist working at Berkeley, had shown that it was possible to separate the RNA and protein components of the TMV and then reassemble them to produce a functional virus. Fraenkel-Conrat then went on to recombine protein from one TMV strain and RNA from another strain; the recombinant strains produced viruses with proteins that were typical of the RNA donor strain and never like those found in the protein donor strain. In his 1957 lecture, Crick described this finding and concluded: ‘the viral RNA appears to carry at least part of the information which determines the composition of the viral protein’.
10
For the first time, Crick spelled out the precise implications of the use of the term information in genetics: ‘By information I mean the specification of the amino acid sequence of the protein.’
11
This was not information as Shannon had described it – Crick was not referring to a mathematical measure of the degree of uncertainty of one particular message. He was talking about something much more tangible, straightforward and immediately understandable: the sequence of amino acids in a protein. A gene somehow carried the code that could produce a particular amino acid sequence, and it was also capable of passing that code to the next generation. The information necessary to include a particular amino acid in a protein was encoded by the sequence of bases in the DNA that made up the gene.
Crick then repeated an assertion that he had recently been touting at various conferences: the sequence of amino acids alone was significant in determining protein function. Although the three-dimensional shapes of proteins were ultimately the explanation of specificity, of the myriad functions of proteins, these complex structures were in fact contained within the one-dimensional message of DNA. The three-dimensional protein structure simply emerged out of the one-dimensional DNA code through the process of protein synthesis, argued Crick. Nothing else mattered except the sequence of amino acids, which was in turn determined by the order of bases in the DNA molecule: the genetic code. As Crick put it: ‘It is of course possible that there is a special mechanism for folding up the chain, but the more likely hypothesis is that the
folding is simply a function of the order of the amino acids
’.
12
Crick called this view the sequence hypothesis:
folding is simply a function of the order of the amino acids
’.
12
Crick called this view the sequence hypothesis:
In its simplest form it assumes that the specificity of a piece of nucleic acid is expressed solely by the sequence of its bases, and that this sequence is a (simple) code for the amino acid sequence of a particular protein. This hypothesis appears to be rather widely held.
13
Crick may have though it was ‘widely held’, but plenty of scientists were deeply suspicious of Crick’s view.
In June 1956, Erwin Chargaff, in typically contrarian and acerbic mood, complained that too much attention was being paid to nucleic acids, and he still wondered whether there was something else apart from DNA that was giving proteins their final shape:
It is obvious that sequence cannot be the sole agent of biological information. Even if the arrangement of an entire polynucleotide would be written, a third dimension would be lacking: the operative three-dimensional shape of the molecular aggregate, in which perhaps not only numerous nucleic acid molecules take part, but also proteins and possibly even other polymers’.
14
Another doubter was Macfarlane Burnet, who had just published a short book called
Enzyme, Antigen and Virus: A Study of Macromolecular Pattern in Action.
Burnet’s book had made an impression on Crick because it took an opposing stance to him on many points. In his book, Burnet declared that it was ‘quite impossible at the present time’ to envisage how a nucleic acid could specify a linear polypeptide sequence; like Chargaff, instead of relying totally on DNA, Burnet wanted to ‘leave open the possibility of some associated factor, histone possibly, which allows a sufficient complexity to carry the needed coding.’
15
Even leading scientific figures were clinging to the idea that proteins must play an essential role in genetics.
Enzyme, Antigen and Virus: A Study of Macromolecular Pattern in Action.
Burnet’s book had made an impression on Crick because it took an opposing stance to him on many points. In his book, Burnet declared that it was ‘quite impossible at the present time’ to envisage how a nucleic acid could specify a linear polypeptide sequence; like Chargaff, instead of relying totally on DNA, Burnet wanted to ‘leave open the possibility of some associated factor, histone possibly, which allows a sufficient complexity to carry the needed coding.’
15
Even leading scientific figures were clinging to the idea that proteins must play an essential role in genetics.
Part of the problem was that no one knew exactly how a cell took a nucleic acid sequence and turned it into a blob of protein made up of amino acids. It was known that the main steps of protein synthesis took place in the cell’s cytoplasm, which surrounds the nucleus. On the one hand, DNA was known to stay in the nucleus, so it was clearly not directly involved; on the other hand, RNA was found throughout the cell in a variety of forms, apparently associated with the synthesis of proteins. It looked as though the genetic message passed from DNA to RNA, but how this happened was unclear. It was equally uncertain how the amino acid chain was assembled to make a protein, although small recently discovered RNA-rich structures called microsomal particles seemed to be involved. Informal discussion at a conference in 1958 led to these particles being re-baptised ‘ribosomes’, by which name they are known today.
16
A few weeks before Crick’s talk, Mahlon Hoagland and Paul Zamecnik at Harvard had shown that if amino acids were radioactively labelled, proteins throughout the cell were eventually found to be radioactive, indicating that the amino acids had been assembled into a protein.
17
On shorter time-scales, however, radioactivity was found only in the ribosomes, strongly suggesting that amino acids had to pass through the ribosome to be combined into a protein.
18
It seemed likely that the RNA in the ribosome was the actual site where the protein was made. This raised the question of the nature of the link between DNA and RNA, and how each amino acid found its way to the ribosome.
16
A few weeks before Crick’s talk, Mahlon Hoagland and Paul Zamecnik at Harvard had shown that if amino acids were radioactively labelled, proteins throughout the cell were eventually found to be radioactive, indicating that the amino acids had been assembled into a protein.
17
On shorter time-scales, however, radioactivity was found only in the ribosomes, strongly suggesting that amino acids had to pass through the ribosome to be combined into a protein.
18
It seemed likely that the RNA in the ribosome was the actual site where the protein was made. This raised the question of the nature of the link between DNA and RNA, and how each amino acid found its way to the ribosome.
In his lecture, Crick turned his brilliant mind to both these issues and publicly described the idea he had worked up with Brenner: there must be an unknown class of small molecule, which they called an adaptor, which would gather each of the twenty amino acids and take them to the ribosome, so that the protein could be assembled there. The most likely hypothesis was that there was one adaptor for each type of amino acid, and that it would contain a short stretch of nucleotides – a tiny bit of the genetic code that was able to bind to the RNA template in the ribosome, just like base pairing between the two strands of the DNA double helix. At the same time, on the other side of the Atlantic, Hoagland and Zamecnik were isolating what was later identified as Crick’s adaptor – eventually known as transfer RNA or tRNA – without knowing anything about Crick’s hypothesis.
19
19
To put all this speculation into a theoretical context, Crick explained to his audience that there were three ways of understanding the processes involved in protein synthesis – ‘the flow of energy, the flow of matter, and the flow of information.’
20
He focused on the final, most elusive, and most radical aspect – the flow of information. In both his lecture and the
Scientific American
article that appeared at the same time, Crick used a memorable term to describe a fundamental feature of genes: he outlined what he called ‘the central dogma’ of genetics. Crick explained this dogma as follows:
20
He focused on the final, most elusive, and most radical aspect – the flow of information. In both his lecture and the
Scientific American
article that appeared at the same time, Crick used a memorable term to describe a fundamental feature of genes: he outlined what he called ‘the central dogma’ of genetics. Crick explained this dogma as follows:
once information (meaning here the determination of a sequence of units) has been passed into a protein molecule it cannot get out again, either to form a copy of the molecule or to affect the blueprint of a nucleic acid. The idea is not universally accepted, however. In fact, Sir Macfarlane Burnet, the eminent Australian virologist, persuasively argued another point of view in a very interesting little book which he published recently.
21
On the basis of the available molecular evidence, Crick was arguing that there were four kinds of information transfer that were likely to take place routinely: DNA → DNA (as in DNA duplication), DNA → RNA (as in the first step of protein synthesis), RNA → protein (as in the second step of protein synthesis) and RNA → RNA (presumed to exist because of the existence of RNA viruses such as TMV, which used RNA both to store information and to synthesise proteins and were able to copy themselves). Crick agreed that there were also two possible information transfers that might conceivably take place, but for which there was no evidence: DNA → protein (this would occur if protein synthesis took place directly on the DNA molecule, which seemed unlikely) and RNA → DNA (there was no evidence for this, nor any biological process that seemed to require it, but it was not seen as structurally impossible).
There were several genetic information transfers that Crick and his colleagues considered to be impossible: protein → protein (this had been disproved by the work of Avery, Hershey and Chase and others), protein → RNA and, above all, protein → DNA. There was no evidence for any of these information flows, nor was there any conceivable mechanism for the sequence of amino acids being back-translated into a DNA or RNA code. As Crick later put it, ‘I decided, therefore, to play safe, and to state as the basic assumption of the new molecular biology the non-existence of [these] transfers’.
22
This was the ‘central dogma’: once information had gone from DNA into the protein, it could not get out of the protein and go back into the genetic code.
22
This was the ‘central dogma’: once information had gone from DNA into the protein, it could not get out of the protein and go back into the genetic code.
*
Crick had first come up with the ‘central dogma’ phrase and its underlying concept in October 1956, in a set of notes entitled ‘Ideas on protein synthesis’.
23
These were not circulated – not even to the RNA Tie Club – but they formed the basis of his discussions with his colleagues and his thinking over the following months. In those original notes – but not in either of the published forms of his talk – Crick included a little diagram to show what he meant.
23
These were not circulated – not even to the RNA Tie Club – but they formed the basis of his discussions with his colleagues and his thinking over the following months. In those original notes – but not in either of the published forms of his talk – Crick included a little diagram to show what he meant.
On the original note, Crick playfully wrote ‘The doctrine of the Triad’ (DNA, RNA and protein), but he soon coined the more dramatic term ‘central dogma’. As was evident from his presentation of the idea in 1957, it was not, strictly speaking, a dogma (a fundamental belief that cannot be questioned). It was instead a hypothesis, and rather than being based on any a priori position, it was simply based on the available data. Crick later recalled:
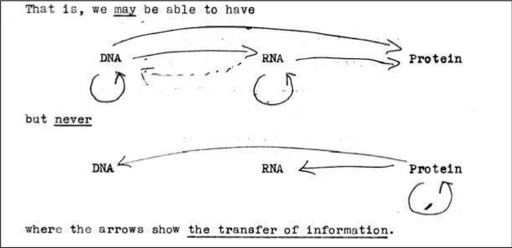
5. Crick’s first outline of the central dogma, 1956, http://profiles.nlm.nih.gov/ps/access/SCBBFT.pdf
I called this idea the central dogma, for two reasons, I suspect. I had already used the obvious word hypothesis in the sequence hypothesis, and in addition I wanted to suggest that this new assumption was more central and more powerful. I did remark that their speculative nature was emphasized by their names. As it turned out, the use of the word dogma caused almost more trouble than it was worth. Many years later Jacques Monod pointed out to me that I did not appear to understand the correct use of the word dogma, which is a belief that cannot be doubted. I did apprehend this in a vague sort of way but since I thought that all religious beliefs were without any serious foundation, I used the word in the way I myself thought about it, not as most of the rest of the world does, and simply applied it to a grand hypothesis that, however plausible, had little direct experimental support.
24
As well as predicting the results of future experiments, Crick was unwittingly supporting two of the central tenets of twentieth-century biology. First, there was the assumption, suggested by August Weismann in the 1890s, that in animals the organism contains two entirely separate cell lines, one devoted to the development of the body (the somatic line) and the other to reproduction and the transmission of hereditary characters (the germ line) (no such division exists in plants or, obviously, in single-celled organisms; it is also absent in some animals). According to Weismann, these two cell lines did not interact. As a result, it was impossible for any character that was acquired during an animal’s life and which affected the somatic line, to have any effect on the germ line, on heredity. In Crick’s language, information could not go in the direction protein → DNA.
By providing a molecular basis for Weismann’s position, Crick was also reinforcing the widespread opposition to the suggestion by the nineteenth-century naturalist Lamarck (and also Darwin) that characters acquired by an organism during its lifetime could have an effect on its offspring by altering its hereditary constitution. In Weismann’s model, there was simply no route for this to occur. During the 1920s and 1930s, Weismann’s division of cell types became a cornerstone of what was known as the neo-Darwinian synthesis as genetics and evolutionary theory fused, changing the way in which scientists looked at evolution by natural selection. In 1957 Crick said essentially the same thing as Weismann, but in the latest language and with a far greater import, because it applied to all organisms, not just animals: once information had got into the protein, it could not get out again. It could not go back into the DNA. Although not a dogma, this was a very strong assertion. As Crick later reflected: ‘In looking back I am struck … by the brashness which allowed us to venture powerful statements of a very general nature.’
25
25
Other books
Duet for Three Hands by Tess Thompson
X-Treme Latin: Lingua Latina Extrema by Henry Beard
Angel Betrayed by Cynthia Eden
Star Wars: The Old Republic: Fatal Alliance by Sean Williams
What a Woman Desires by Rachel Brimble
[04] Elite: Mostly Harmless by Kate Russell
Naughty in November (Spring River Valley Book 11) by Wynter, Clarice
Judith E. French by Moon Dancer
Master of Seduction by Kinley MacGregor