What Mad Pursuit (23 page)
Authors: Francis Crick

Workers in brain theory are thus pulled in several directions. Intellectual snobbery makes them feel they should produce results that are mathematically both deep and powerful and also apply to the brain. This is not likely to happen if the brain is really a complicated combination of rather simple tricks evolved by natural selection. If an idea they conceive doesn’t help to explain the brain, the theorists may hope that perhaps it may be useful in AI. There is thus no compelling drive for them to press on and on until the way the brain actually works is laid bare. It is more fun to produce “interesting” computer programs and much easier to get grants for such work. There is even the possibility that they might make some money if their ideas could be used in computers. The situation is not helped by the general view that psychology is a “soft” science, which seldom if ever produces definitive results but stumbles from one theoretical fad to the next one. Nobody likes to ask if a model is really correct since, if they did, most work would come to a halt.
I wish I could say that my own efforts amounted to much. From thinking about neural nets Graeme Mitchison and I invented in 1983 a new reason for the existence of rapid-eye-movement (REM) sleep, though two other groups independently thought of the same mechanism. This is a lot of fun to lecture about since almost everybody is interested in sleep and dreams. I have given the lecture to physicists (including the research department of an oil company), women’s clubs, and high-school teachers as well as to numerous academic departments. The essence of the idea is that memories are likely to be stored in the mammalian brain in a very different way from the way they are stored in a filing system or in a modern computer. It is widely believed that, in the brain, memories are both “distributed” and to some extent superimposed. Simulations show that this need not cause a problem unless the system becomes overloaded, in which case it can throw up false memories. Often these are mixtures of stored memories that have something in common.
Such mixtures immediately remind me of dreams and of what Freud called condensation. For example, when we dream of someone, the person in the dream is usually a mixture of two or three rather similar people. Graeme and I therefore proposed that in REM sleep (sometimes called dream sleep), there is an automatic correction mechanism that acts to reduce this possible confusion of memories. We suggest that this mechanism is the root cause of our dreams, most of which, incidentally, are not remembered at all. Whether this idea is true or not only time will tell.
I also wrote a paper on the neural basis of attention, but this also is highly speculative. I have yet to produce any theory that is both novel and also explains many disconnected experimental facts in a convincing way.
Looking back, I can recall how very strange I found this new field. There is no doubt that, compared to molecular biology, brain science is in an intellectually backward state. Also the pace is much slower. One can see this by noting the use of the word recently. In classical studies (Latin and Greek) “recently” means within the last twenty years. In neurobiology or psychology it usually means within the last few years, whereas in modern molecular biology it means within the last few
weeks.
Three main approaches are needed to unscramble a complicated system. One can take it apart and characterize all the isolated bits—what they are made of and how they work. Then one can find exactly where each part is located in the system in relation to all the other parts and how they interact with each other. These two approaches are unlikely, by themselves, to reveal exactly how the system works. To do this one must also study the behavior of the system and its components while interfering very delicately with its various parts, to see what effect such alterations have on behavior at all levels. If we could do all this to our own brains we would find out how they work in no time at all.
Molecular and cell biology could help decisively in all these three approaches. The first has already begun. For example, the genes for a number of the key molecules have already been isolated, characterized, and their products produced so that they can be more easily studied. A little progress has been made on the second approach, but more is still needed. For example, a technique for injecting a single neuron in such a way that all the neurons connected to it (and only those) are labeled would be useful.
The third approach also needs new methods, especially as the usual ways of ablating parts of the brain are so crude. For example, it would be useful to be able to inactivate, preferably reversibly, a single type of neuron in a single area of the brain. In addition, more subtle and powerful ways of studying behavior, both of the whole animal and also of groups of neurons, are needed. Molecular biology is advancing so rapidly that it will soon have a massive impact on all aspects of neurobiology.
In the summer of 1984 I was asked to address the Seventh European Conference on Visual Perception in Cambridge, England. It was one of those after-dinner occasions when one is expected to entertain as well as to inform. I finished by stating that in a generation’s time most of the researchers in psychology departments would be working on “molecular psychology.” I could see expressions of total disbelief on the faces of most of my audience. “If you don’t accept that,” I said, “look what has happened to
biology
departments. Nowadays most of the scientists there are doing
molecular
biology, whereas a generation ago that was a subject known only to specialists.” Their disbelief changed to apprehension. Is
that
what the future had in store? The last couple of years has shown that the beginning of this trend is already with us [recent work on the NMDA receptor for glutamate and its relation to memory, for example].
The present state of the brain sciences reminds me of the state of molecular biology and embryology in, say, the 1920s and 1930s. Many interesting things have been discovered, each year steady progress is made on many fronts, but the major questions are still largely unanswered and are unlikely to be without new techniques and new ideas. Molecular biology became mature in the 1960s, whereas embryology is only just starting to become a well-developed field. The brain sciences have still a very long way to go, but the fascination of the subject and the importance of the answers will inevitably carry it forward. It is essential to understand our brains in some detail if we are to assess correctly our place in this vast and complicated universe we see all around us.
A Brief Outline
of Classical
Molecular Biology
T
HE GENETIC MATERIAL of all organisms in nature is nucleic acid. There are two types of nucleic acid: DNA (short for deoxyribonucleic acid) and the closely related RNA (short for ribonucleic acid). Some small viruses use RNA for their genes. All other organisms and viruses use DNA. (Slow viruses may be an exception.)
The molecules of both DNA and RNA are long and thin, sometimes extremely long. DNA is a polymer, with a regular backbone, having alternating phosphate groups and sugar groups (the sugar is called deoxyribose).
To each sugar group is attached a small, flat, molecular group called a base. There are four major types of base, called A (adenine), G (guanine), T (thymine), and C (cytosine). (A and G are purines; T and C are pyrimidines.) The
order
of the bases along any particular stretch of DNA conveys the genetic information. By 1950 Erwin Chargaff had discovered that in DNA from many different sources the amount of A equaled the amount of T, and the amount of G equaled the amount of C. These regularities are known as Chargaff’s rules.
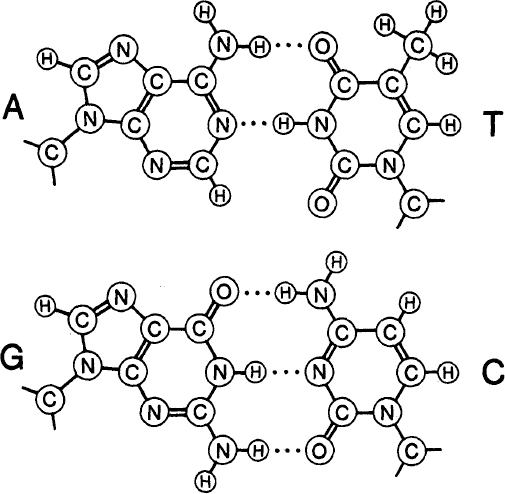
The two base pairs: A=T and G≡C For the bases: A—Adenine, T—Thymine, G—Guanine, C—Cytosine. For the atoms: C—Carbon, N—Nitrogen, O—Oxygen, H—Hydrogen.
RNA is similar in structure to DNA, except that the sugar is slightly different (ribose instead of deoxyribose) and instead of T there is U (uracil). (Thymine itself is 5-methyl-uracil.) Thus, the AT pair is replaced by the very similar AU pair.
DNA is usually found in the form of a double helix, having two distinct chains wound around one another about a common axis. Surprisingly, the two chains run in
opposite
directions. That is, if the sequence of atoms in the backbone of one chain runs up, then that of the other runs down.
At any level the bases are paired. That is, a base on one chain is paired with the base opposite it on the other chain. Only certain pairs are possible. They are:
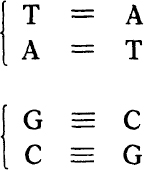
Their chemical formulas are shown in
figure A-1
. These base pairs are held together by weak bonds, called hydrogen bonds, symbolicized here by the dashes. Thus the AT pair forms two hydrogen bonds, the GC pair three of them.
This pairing of the bases is the key feature of the structure.
To replicate DNA, the cell unwinds the chains and uses each single chain as a template to guide the formation of a new companion chain. After this process is completed we are left with
two
double helices, each containing one old chain and one new one. Since the bases for the new chains must be selected to obey the pairing rules (A with T, G with C), we end up with
two
double helices, each identical in base sequence to the one we started with. In short, this neat pairing mechanism is the molecular basis for like reproducing like. The actual process is a lot more complicated than the outline just sketched.
A major function of nucleic acid is to code for protein. A protein molecule is also a polymer, with a regular backbone (called a polypeptide chain) and side groups attached at regular intervals. Both backbone and side-chains of protein are quite different chemically from the backbone and side groups of nucleic acid. Moreover, there are twenty different side groups found in proteins, compared with only four in nucleic acid.
The general chemical formula of a polypeptide chain is shown in
figure A-2
. The “side-chains” are attached at the points marked R, R’, R", and so forth. The exact chemical formula of each of the twenty different side-chains is known and can be found in any textbook of biochemistry.
Each polypeptide chain is formed by joining together, head to tail, little molecules called amino acids. The general formula for an amino acid appears in
figure A-3
, where R represents the side-chain that is different for each of the magic twenty. During this process one molecule of water is eliminated as each join is made. (The actual chemical steps are a little more complicated than this simple, overall description.)
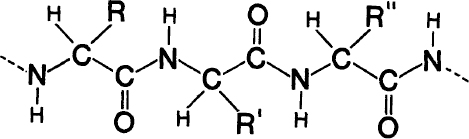
The basic chemical formula for a polypeptide chain (approximately three repeats are shown). C—Carbon, N—Nitrogen, 0—Oxygen, H—Hydrogen. R, R’, R"—the various side-chains (R stands for Residue).
All the amino acids inserted into proteins (except glycine) are L-amino acids, as opposed to their mirror images, which are called D-amino acids. This terminology refers to the three-dimensional configuration around the upper carbon atom in
figure A-3
.
The synthesis of a protein takes place on a complicated piece of biochemical machinery, called a ribosome, aided by a set of small RNA molecules called tRNA (transfer RNA) and a number of special enzymes. The sequence information is provided by a type of RNA molecule called mRNA (messenger RNA). In most cases this mRNA, which is single-stranded, is synthesized as a copy of a particular stretch of DNA, using the base-pairing rules. A ribosome travels along a piece of mRNA, reading off its base sequence in groups of three at a time, as explained in appendix B. The overall process is DNA ~~> mRNA ~~> protein, where the wiggly arrows show the direction in which the sequence information is transferred.
To make matters even more complicated, each ribosome is constructed not only with a large set of protein molecules but also with several molecules of RNA, two of them being fairly large. These RNA molecules are
not
messengers. They form part of the ribosomal structure.
As a polypeptide chain is synthesized, it folds itself up to form the intricate three-dimensional structure that protein needs to perform its highly specific function.
Proteins come in all sizes. A typical one might be several hundred’ side groups long. Thus a gene is often a stretch of DNA, typically about a thousand or more base pairs long, that codes for a single polypeptide chain. Other parts of the DNA are used as control sequences, to help turn particular genes on and off.
The nucleic acid of a small virus may be about 5, 000 bases long and will code for a handful of proteins. A bacterial cell is likely to have some million bases in its DNA, often all in one circular piece, and code for several thousand different kinds of protein. One of your own cells has about three billion bases from your mother and a similar number from your father, coding for some 100, 000 kinds of proteins. It was discovered in the 1970s that the DNA of higher organisms may contain long stretches of DNA (some of which occur
within
genes, and are called introns) with no apparent function.
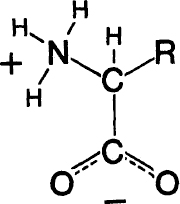
The general formula for an amino acid. The amino group is NH
3
+
. The acid group is COO
-
. The side-group, which differs from one amino acid to another, is denoted R. C—Carbon, N—Nitrogen, O—Oxygen, H—Hydrogen.
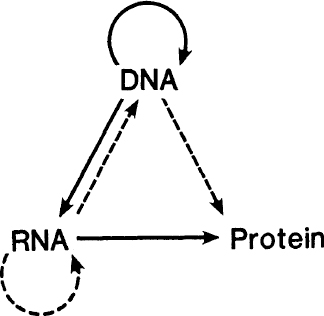
A diagram to illustrate the central dogma. The arrows represent the various transfers of sequence information. Solid arrows show the common transfers. Dotted arrows show the rarer transfers. Notice that the missing transfers are those for which the arrows would start from protein.
The so-called central dogma is a grand hypothesis that attempts to predict which transfers of sequence information
cannot
take place. These correspond to the missing arrows in
figure A-4
. The common transfers are shown by the solid lines; the rarer ones by the dotted ones. Note that the missing arrows correspond to all possible transfers
from
protein.
The common transfers have been described earlier. Of the rarer ones the transfer RNA ~> RNA is used by certain RNA viruses, such as the flu virus and the polio virus. The transfer RNA ~> DNA (reverse transcription) is used by the so-called RNA retroviruses. An example is the AIDS virus. The transfer DNA ~> protein is a freak. Under special conditions in the test tube, single-stranded DNA can act as a messenger, but this probably never occurs in nature.