XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (17 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

Despite its disparate syntactic roots and its lexical quirks, XPath has managed to integrate these different kinds of expression surprisingly well. In particular, it has retained full composability within itself, so any kind of expression can be nested inside any other.
Summary
This introductory chapter answered the following questions about XSLT:
- What kind of language is it?
- How is it used?
- Where does it fit into the XML family?
- Where does it come from and why was it designed the way it is?
You now know that XSLT is a declarative high-level language designed for transforming the structure of XML documents; that it has two major applications: data conversion and presentation; and that it can be used at a number of different points in the overall application architecture, including at data capture time, at delivery time on the server, and at display time on the browser. You also have some idea why XSLT has developed in the way it has.
Now it's time to start taking an in-depth look inside the language to see how it does this job. In the next chapter, we look at the way transformation is carried out by treating the input and output as tree structures, and using patterns to match particular nodes in the input tree and define what nodes should be added to the result tree when the pattern is matched.
Chapter 2
The XSLT Processing Model
This chapter takes a bird's-eye view of what an XSLT processor does. We start by looking at a system overview: what are the inputs and outputs of the processor?
Then we look in some detail at the data model, in particular the structure of the tree representation of XML documents. An important message here is that XSLT transformations do not operate on XML documents as text; they operate on the abstract tree-like information structure represented by the markup.
Having established the data model, I will describe the processing sequence that occurs when a source document and a stylesheet are brought together. XSLT is not a conventional procedural language; it consists of a collection of template rules defining output that is produced when particular patterns are matched in the input. As seen in Chapter 1, this rule-based processing structure is one of the distinguishing features of the XSLT language.
Finally, we look at the way in which variables and expressions can be used in an XSLT stylesheet, and also look at the various data types available.
XSLT: A System Overview
This section looks at the nature of the transformation process performed by XSLT, concentrating on the inputs and outputs of a transformation.
A Simplified Overview
The core task of an XSLT processor is to apply a stylesheet to a source document and produce a result document. This is shown in
Figure 2-1
.
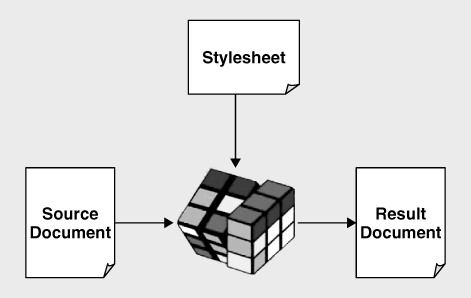
As a first approximation we can think of the source document, the stylesheet, and the result document as each being an XML document. XSLT performs a
transformation
process because the
output
(the result document) is the same kind of object as the
input
(the source document). This has immediate benefits: for example, it is possible to do a complex transformation as a series of simple transformations, and it is possible to do transformations in either direction using the same technology.
The choice of Rubik's cube to illustrate the transformation process is not entirely whimsical. The mathematics of Rubik's cube relies on group theory, which is where the notion of closure comes from: every operation transforms one instance of a type into another instance of the same type. We're transforming XML documents rather than cubes, but the principle is the same.
The name
stylesheet
has stuck for the document that defines the transformation, despite the fact that XSLT is often used for tasks that have nothing to do with styling. The name reflects the reality that a very common kind of transformation performed using XSLT is to define a display style for the information in the source document, so that the result document contains information from the source document augmented with information controlling the way it is displayed on some output device.
Trees, Not Documents
In practice, we don't always want the input or output to be XML in its textual form. If we want to produce HTML output (a very common requirement), we want to produce it directly, rather than having an XML document as an intermediate form. When the Firefox browser displays the result of an XSLT transformation, it doesn't serialize the result to HTML and then parse the textual HTML; rather, it works directly from the result tree as a data structure in memory. Similarly, we might want to take input from a database or (say) an LDAP directory, or an EDI message, or a data file using comma-separated-values syntax. We don't want to spend a lot of time converting these into serial XML documents if we can avoid it, nor do we want another raft of converters to install.
Instead, XSLT defines its operations in terms of a data model (called XDM) in which an XML document is represented as a
tree
. The tree is an abstract data type. There is no defined application programming interface (API) and no defined data representation, only a conceptual model that defines the objects in the tree, their properties, and their relationships. The XDM tree is similar in concept to the W3C DOM, except that the Document Object Model (DOM) does have a defined API. Some implementors do indeed use the DOM as their internal tree structure. Others use a data structure that corresponds more closely to the XDM specification, while some use optimized internal data structures that are only distantly related to this model. It's a conceptual model we are describing, not something that necessarily exists in an implementation.
The data model for XSLT trees is shared with the XPath and XQuery specifications, which ensures that data can be freely exchanged between these three languages (it also means you can take your pick as to what the “X” in “XDM” stands for). With XSLT and XPath, this is of course essential, because XSLT always retrieves data from a source document by executing XPath expressions. There is a description of this data model later in this chapter, and full details are in Chapter 4.
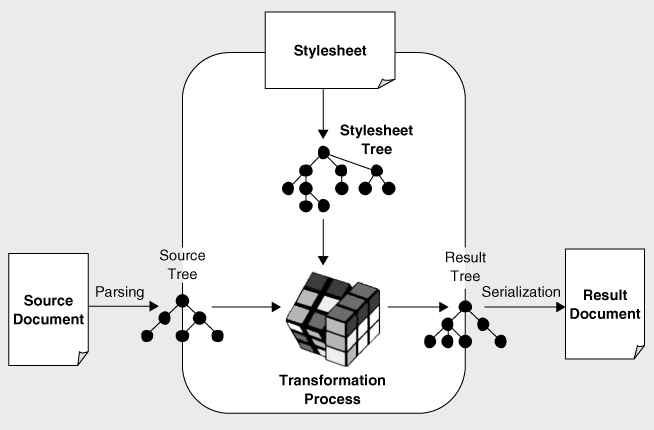
Taking the inputs and output of the XSLT processors as trees produces a new diagram (see
Figure 2-2
). The formal conformance rules say that an XSLT processor must be able to read a stylesheet and use it to transform a source tree into a result tree. This is the part of the system shown in the oval box. There's no official requirement to handle the parts of the process shown outside the box, namely the creation of a source tree from a source XML document (known as
parsing
), or the creation of a result XML document from the result tree (called
serialization
). In practice, though, most real products are likely to handle these parts as well.
Different Output Formats
Although the final process of converting the result tree to an output document is outside the conformance rules of the XSLT standard, this doesn't mean that XSLT has nothing to say on the subject.
The main control over this process is the
xml
,
html
,
xhtml
, and
text
. In each case a result tree is written to a single output file.
- With the
xml
output method, the output file is an XML document. We'll see later that it need not be a complete XML document; it can also be an XML fragment. The
CDATA
sections. - With the
html
output method, the output file is an HTML document, typically HTML 4.0, though products may support other versions if they wish. With HTML output, the XSLT processor recognizes many of the conventions of HTML and structures the output accordingly. For example, it recognizes elements such as
that have a start tag and no end tag, as well as the special rules for escape characters within a