XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (255 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

This stylesheet demonstrates a mixture of rigidly structured data processed using
pull
processing, and narrative markup processed using
push
processing. The great advantage of the
push
approach is that the rules are written making no assumptions about the way the markup tags are nested in the source document. It is very easy to add new rules for new tags and to reuse rules if an existing tag is used in a new context.
Where the nesting of elements is more rigid, this very flexible rule-based style of processing has fewer benefits, so the
pull
programming style using
Using Modes
The classic reason for using modes is to enable the same content to be processed more than once in different ways; for example, the first pass through the document might generate the table of contents, the second pass the actual text, and the third pass an index.
Example: Using modes
The source document is a concert review in the same format as in the previous example. This time, however, the requirement is to produce at the end of the review a list of works mentioned in the text.
Source
The source file is
review.xml
. See previous example.
Stylesheet
The stylesheet file is
review + index.xsl
.
This stylesheet extends the previous one using match=“text()”
match=“text()” to ensure that when the text is processed withmode=“index”, nothing is output. The only output comes from the template rule that matches
to ensure that when the text is processed withmode=“index”, nothing is output. The only output comes from the template rule that matches
xmlns:xsl=“http://www.w3.org/1999/XSL/Transform”>
Index of Works
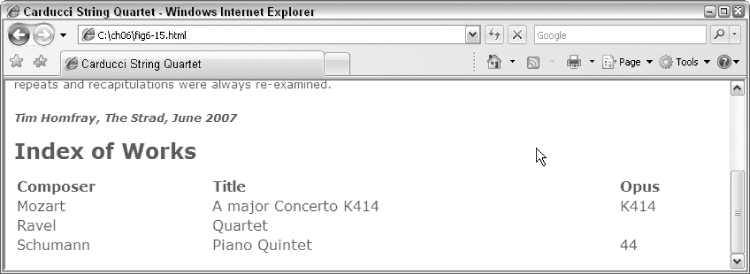
Output
The output is as shown in
Figure 6-15
.
See Also
generate-id()
function in Chapter 7, on page 797
xsl:text
The
Changes in 2.0
None.
Format
disable-output-escaping? = “yes” | “no”>
Position
Attributes
| Name | Value | Meaning |
| disable-output-escaping optional, deprecated |  yes yes orno orno | The valueyesindicates that special characters in the output (such as<) should be output as is, rather than using an XML escape form such as<. The default value isno. |