XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (535 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

, but not (and here's the surprise) when it is co
co .
.
I've written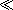 garc,on
garc,on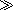 to illustrate that thecand the cedilla are two separate Unicode codepoints. But of course the cedilla is actually a nonspacing character, so in real life this string of seven codepoints would appear on the page asgar
to illustrate that thecand the cedilla are two separate Unicode codepoints. But of course the cedilla is actually a nonspacing character, so in real life this string of seven codepoints would appear on the page asgar
ç
on.
Java could instead have standardized on the composed form of the character, but the accent-blind matching would then not work:contains(“gar
ç
on”, “c”)would be false.
Now let's look at a case where a pair of characters represents a single collation unit. Here we turn back to Spanish, where in older publicationschcollates aftercandllcollates afterl. We can set this up in Java by defining a
RuleBaseCollator
using a rule that definesc
<
ch
<
dandl
<
ll
<
m. (Modern Spanish practice follows the English collating rules, so I had to set up these rules myself.)