XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (786 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

The document identified by the stylesheet property must be a free-threaded document object.
Putting it Together
The example in this section shows one way of controlling a transformation using MSXML from within JavaScript on an HTML page.
Example: Using Client-Side JScript to Transform a Document
This example demonstrates the way that you can load, parse, and transform an XML document using client-side JScript in Internet Explorer. You can run this simply by loading the page
default.html
using the IE browser (version 5 or higher). When you first load it, you may see a security warning, depending on your browser security settings. If this happens, right-click on the message and select “Allow blocked content”.
The example shows an HTML page with two buttons on it. The user can click on either of the buttons to select how the data should be displayed. The effect of clicking either button is to apply the corresponding stylesheet to the source XML document.
XML Source
The XML source file for this example is
tables
_
data.xml
. It defines several tables (real tables, the kind you sit at to have your dinner), each looking like this:
…
Stylesheet
There are two stylesheet files,
tables
_
list.xsl
and
tables
_
catalog.xsl
. Since this example is designed to show the JScript used to control the transformation rather than the XSLT transformation code itself, I won't list them here.
HTML page
The page
default.htm
contains some simple styling information for the HTML page, then the JScript code that loads the XML and XSL documents, checks for errors, and performs the transformation. Notice that the
transformFiles
function takes the name of a stylesheet as a parameter, which allows you to specify the stylesheet you want to use at runtime:
body {font-family:Tahoma,Verdana,Arial,sans-serif;
font-size:14px}
head {font-family:Tahoma,Verdana,Arial,sans-serif;
font-size:18px; font-weight:bold}
function transformFiles(strStylesheetName) {
// get a reference to the results DIV element
var objResults = document.all[‘divResults’];
// create two new document instances
var objXML = new ActiveXObject(‘MSXML2.DOMDocument.3.0’);
var objXSL = new ActiveXObject(‘MSXML2.DOMDocument.3.0’);
// set the parser properties
objXML.validateOnParse = true;
objXSL.validateOnParse = true;
// load the XML document and check for errors
objXML.load(‘tables_data.xml’);
if (objXML.parseError.errorCode != 0) {
// error found so show error message and stop
objResults.innerHTML = showError(objXML)
return false;
}
// load the XSL stylesheet and check for errors
objXSL.load(strStylesheetName);
if (objXSL.parseError.errorCode != 0) {
// error found so show error message and stop
objResults.innerHTML = showError(objXSL)
return false;
}
// all must be OK, so perform transformation
strResult = objXML.transformNode(objXSL);
// and display the results in the DIV element
objResults.innerHTML = strResult;
return true;
}
Provided that there are no errors, the function performs the transformation using the XML file
tables
_
data.xml
and the stylesheet whose name is specified as the
strStylesheet Name
parameter when the function is called.
The result of the transformation is inserted into the If either of the function showError(objDocument) // create the error message var strError = new String; strError = ‘Invalid XML file ! + ‘File URL: ’ + objDocument.parseError.url + ‘ + ‘Line No.: ’ + objDocument.parseError.line + ‘ + ‘Character: ’ + objDocument.parseError.linepos + ‘ + ‘File Position: ’ + objDocument.parseError.filepos + ‘ + ‘Source Text: ’ + objDocument.parseError.srcText + ‘ + ‘Error Code: ’ + objDocument.parseError.errorCode + ‘ + ‘Description: ’ + objDocument.parseError.reason return strError; } //--> The remainder of the file is the HTML that creates the visible part of the page. The opening … the client-side code … Because it uses the value The next thing in the page is the code that creates the two HTML … View the tables as a (‘tables_catalog.xsl’)”>Catalog or as a Finally, at the end of the code, you can see the definition of the Output When the page is first displayed, it looks like Click the Restrictions Microsoft claims full compliance with XSLT 1.0 and XPath 1.0, although there are one or two gray areas where its interpretation of the specification may cause stylesheets to be less than 100% portable. These include:
element that has the
id
attribute value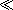 divResults
divResults . You'll later see where this is defined in the HTML.
. You'll later see where this is defined in the HTML.
load
calls fails, perhaps due to a badly formed document, a function named
showError
is called. This function takes a reference to the document where the error was found, and returns a string describing the nature of the error. This error message is then displayed on the page instead of the result of the transformation:
element specifies an
onload
attribute that causes the
transformFiles()
function in our script section to run once the page has finished loading:tables_list.xslfor the parameter to the function, this stylesheet is used for the initial display. This shows the data in tabular form.
elements, marked
Catalog
and
Simple List
. The
onclick
attributes of each one simply execute the
transformFiles()
function again, each time specifying the appropriate stylesheet name:
Figure D-1
.
Catalog
button, and you will see an alternative graphical presentation of the same data, achieved by applying the other stylesheet.
preserveWhitespace
property of the
DOMDocument
object to
True
, before loading the document. The same applies to the stylesheet; if you want to use
preserveWhitespace
set to
True
. It's not possible to preserve whitespace, unfortunately, when stylesheets are loaded into the browser using the
processing instruction.
CDATA
section in the source XML, and secondly, when one of them represents the expanded text of an entity reference (other than the built-in entity references such as <
< ). This makes it dangerous to use a construct such as
). This makes it dangerous to use a construct such as
CDATA
boundary. It's safer to output the value of an element by writingterminate=“yes”.