XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (9 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

Once this rule is triggered, the body of the template says what output to generate. Most of the template body here is a sequence of HTML elements and text to be copied into the output file. There's one exception: an
xsl
. This particular instruction copies the textual content of a node in the source document to the output document. The
select
attribute of the element specifies the node for which the value should be evaluated. The XPath expression greeting
greeting means “find the set of all
means “find the set of all
All that remains is to finish what we started.
Why would you want to place today's greeting in a separate XML file and display it using a stylesheet? One reason is that you might want to show the greeting in different ways, depending on the context; for example, it might be shown differently on a different device, or the greeting might depend on the time of day. In this case, you could write a different stylesheet to transform the same source document in a different way. This raises the question of how a stylesheet gets selected at runtime. There is no single answer to this question; it depends on the product you are using.
With Saxon, we used the
-a
option to process the XML document using the stylesheet specified in its
processing instruction. Instead, we could simply have specified the stylesheet on the command line:
java -jar c:\saxon\saxon8.jar -s:hello.xml -xsl:hello.xsl -o:hello.html
Having looked at a very simple XSLT 1.0 stylesheet, let's now look at a stylesheet that uses features that are new in XSLT 2.0.
An XSLT 2.0 Stylesheet
This stylesheet is very short, but it manages to use four or five new XSLT 2.0 and XPath 2.0 features within the space of a few lines. I wrote it in response to a user enquiry raised on the xsl-list at
http://www.mulberrytech.com/
(an excellent place for meeting other XSLT developers with widely varying levels of experience); so it's a real problem, not an invention. The XSLT 1.0 solution to this problem is about 60 lines of code.
Example: Tabulating Word Frequencies
The problem is simply stated: given any XML document, produce a list of the words that appear in its text, giving the number of times each word appears, together with its frequency.
Input
The input can be any XML document. I will use the text of Shakespeare's
Othello
as an example; this is provided as
othello.xml
in the download files for this book.
Output
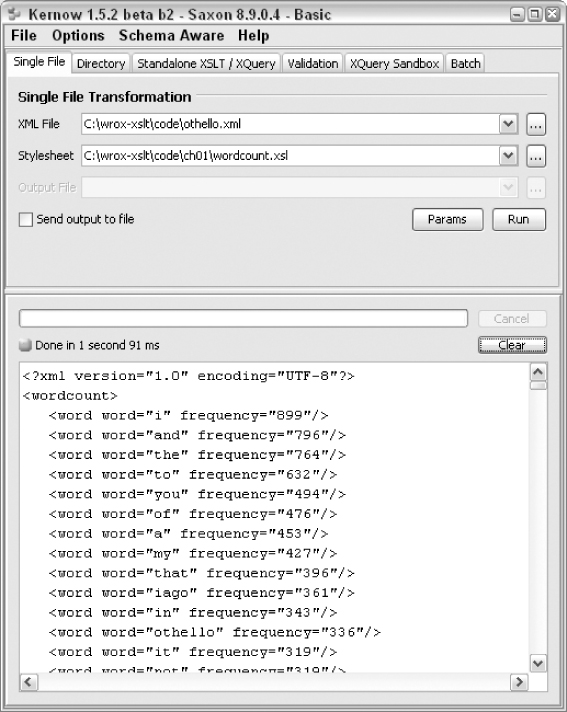
The required output is an XML file that lists words in decreasing order of frequency. If you run the transformation using Kernow, the output appears as shown in
Figure 1-7
.
Stylesheet
Here is the stylesheet that produces this output. You can find it in
wordcount.xsl
.
version=“2.0”
xmlns:xsl=“http://www.w3.org/1999/XSL/Transform”>
for $w in //text()/tokenize(., ‘\W+’)[.!=‘’] return lower-case($w)”>
frequency=“{count(current-group())}”/>
Let's see how this works.
The
The
There is one
To understand the
select
attribute. This contains the XPath 2.0 expression
for $w in //text()/tokenize(., ‘\W+’)[.!=‘’] return lower-case($w)
This first selects//text(), the set of all text nodes in the input tree. It then tokenizes each of these text nodes, that is, it splits it into a sequence of substrings. The tokenizing is done by applying the regular expression\W+. Regular expressions are new in XPath 2.0 and XSLT 2.0, though they will be very familiar to users of other languages such as Perl. They provide the language with greatly enhanced text handling capability. This particular expression,\W+, matches any sequence of one-or-more “non-word” characters, a convenient category that includes spaces, punctuation marks, and other separators. So the result of calling the
tokenize()
function is a sequence of strings containing the words that appear in the text. Because there are text nodes that contain nothing of interest, the result also includes some zero-length tokens, and we filter these out by applying the predicate[.! = ‘’]
The XPathforexpression now applies the function
lower-case()
to each of the strings in this sequence, producing the lower-case equivalent of the word. (Almost everything in this XPath expression is new in XPath 2.0: the
lower-case()
function, the
tokenize()
function, theforexpression, and indeed the ability to manipulate a sequence of strings.)