Data Mining (4 page)
Authors: Mehmed Kantardzic

There is a rapidly widening gap between data-collection and data-organization capabilities and the ability to analyze the data. Current hardware and database technology allows efficient, inexpensive, and reliable data storage and access. However, whether the context is business, medicine, science, or government, the data sets themselves, in their raw form, are of little direct value. What is of value is the knowledge that can be inferred from the data and put to use. For example, the marketing database of a consumer goods company may yield knowledge of the correlation between sales of certain items and certain demographic groupings. This knowledge can be used to introduce new, targeted marketing campaigns with a predictable financial return, as opposed to unfocused campaigns.
The root of the problem is that the data size and dimensionality are too large for manual analysis and interpretation, or even for some semiautomatic computer-based analyses. A scientist or a business manager can work effectively with a few hundred or thousand records. Effectively mining millions of data points, each described with tens or hundreds of characteristics, is another matter. Imagine the analysis of terabytes of sky-image data with thousands of photographic high-resolution images (23,040 × 23,040 pixels per image), or human genome databases with billions of components. In theory, “big data” can lead to much stronger conclusions, but in practice many difficulties arise. The business community is well aware of today’s information overload, and one analysis shows that
1.
61% of managers believe that information overload is present in their own workplace,
2.
80% believe the situation will get worse,
3.
over 50% of the managers ignore data in current decision-making processes because of the information overload,
4.
84% of managers store this information for the future; it is not used for current analysis, and
5.
60% believe that the cost of gathering information outweighs its value.
What are the solutions? Work harder. Yes, but how long can you keep up when the limits are very close? Employ an assistant. Maybe, if you can afford it. Ignore the data. But then you are not competitive in the market. The only real solution will be to replace classical data analysis and interpretation methodologies (both manual and computer-based) with a new data-mining technology.
In theory, most data-mining methods should be happy with large data sets. Large data sets have the potential to yield more valuable information. If data mining is a search through a space of possibilities, then large data sets suggest many more possibilities to enumerate and evaluate. The potential for increased enumeration and search is counterbalanced by practical limitations. Besides the computational complexity of the data-mining algorithms that work with large data sets, a more exhaustive search may also increase the risk of finding some low-probability solutions that evaluate well for the given data set, but may not meet future expectations.
In today’s multimedia-based environment that has a huge Internet infrastructure, different types of data are generated and digitally stored. To prepare adequate data-mining methods, we have to analyze the basic types and characteristics of data sets. The first step in this analysis is systematization of data with respect to their computer representation and use. Data that are usually the source for a data-mining process can be classified into structured data, semi-structured data, and unstructured data.
Most business databases contain structured data consisting of well-defined fields with numeric or alphanumeric values, while scientific databases may contain all three classes. Examples of semi-structured data are electronic images of business documents, medical reports, executive summaries, and repair manuals. The majority of Web documents also fall into this category. An example of unstructured data is a video recorded by a surveillance camera in a department store. Such visual and, in general, multimedia recordings of events or processes of interest are currently gaining widespread popularity because of reduced hardware costs. This form of data generally requires extensive processing to extract and structure the information contained in it.
Structured data are often referred to as traditional data, while semi-structured and unstructured data are lumped together as nontraditional data (also called multimedia data). Most of the current data-mining methods and commercial tools are applied to traditional data. However, the development of data-mining tools for nontraditional data, as well as interfaces for its transformation into structured formats, is progressing at a rapid rate.
The standard model of structured data for data mining is a collection of cases. Potential measurements called features are specified, and these features are uniformly measured over many cases. Usually the representation of structured data for data-mining problems is in a tabular form, or in the form of a single relation (term used in relational databases), where columns are features of objects stored in a table and rows are values of these features for specific entities. A simplified graphical representation of a data set and its characteristics is given in Figure
1.4
. In the data-mining literature, we usually use the terms samples or cases for rows. Many different types of features (attributes or variables)—that is, fields—in structured data records are common in data mining. Not all of the data-mining methods are equally good at dealing with different types of features.
Figure 1.4.
Tabular representation of a data set.
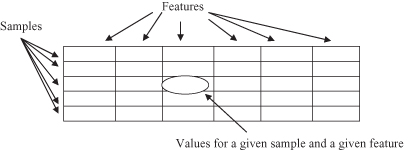
There are several ways of characterizing features. One way of looking at a feature—or in a formalization process the more often used term is variable—is to see whether it is an
independent variable
or a
dependent variable
, that is, whether or not it is a variable whose values depend upon values of other variables represented in a data set. This is a model-based approach to classifying variables. All dependent variables are accepted as outputs from the system for which we are establishing a model, and independent variables are inputs to the system, as represented in Figure
1.5
.
Figure 1.5.
A real system, besides input (independent) variables X and output (dependent) variables Y, often has unobserved inputs Z.

There are some additional variables that influence system behavior, but the corresponding values are not available in a data set during a modeling process. The reasons are different: from high complexity and the cost of measurements for these features to a modeler’s not understanding the importance of some factors and their influences on the model. These are usually called unobserved variables, and they are the main cause of ambiguities and estimations in a model.
Today’s computers and corresponding software tools support processing of data sets with millions of samples and hundreds of features. Large data sets, including those with mixed data types, are a typical initial environment for application of data-mining techniques. When a large amount of data is stored in a computer, one cannot rush into data-mining techniques, because the important problem of data quality has to be resolved first. Also, it is obvious that a manual quality analysis is not possible at that stage. Therefore, it is necessary to prepare a data-quality analysis in the earliest phases of the data-mining process; usually it is a task to be undertaken in the data-preprocessing phase. The quality of data could limit the ability of end users to make informed decisions. It has a profound effect on the image of the system and determines the corresponding model that is implicitly described. Using the available data-mining techniques, it will be difficult to undertake major qualitative changes in an organization based on poor-quality data; also, to make sound new discoveries from poor-quality scientific data will be almost impossible. There are a number of indicators of data quality that have to be taken care of in the preprocessing phase of a data-mining process:
1.
The data should be accurate. The analyst has to check that the name is spelled correctly, the code is in a given range, the value is complete, and so on.
2.
The data should be stored according to data type. The analyst must ensure that the numerical value is not presented in character form, that integers are not in the form of real numbers, and so on.
3.
The data should have integrity. Updates should not be lost because of conflicts among different users; robust backup and recovery procedures should be implemented if they are not already part of the Data Base Management System (DBMS).
4.
The data should be consistent. The form and the content should be the same after integration of large data sets from different sources.
5.
The data should not be redundant. In practice, redundant data should be minimized, and reasoned duplication should be controlled, or duplicated records should be eliminated.
6.
The data should be timely. The time component of data should be recognized explicitly from the data or implicitly from the manner of its organization.
7.
The data should be well understood. Naming standards are a necessary but not the only condition for data to be well understood. The user should know that the data correspond to an established domain.
8.
The data set should be complete. Missing data, which occurs in reality, should be minimized. Missing data could reduce the quality of a global model. On the other hand, some data-mining techniques are robust enough to support analyses of data sets with missing values.
How to work with and solve some of these problems of data quality is explained in greater detail in Chapters 2 and 3 where basic data-mining preprocessing methodologies are introduced. These processes are performed very often using data-warehousing technology, which is briefly explained in Section 1.5.
1.5 DATA WAREHOUSES FOR DATA MINING
Although the existence of a data warehouse is not a prerequisite for data mining, in practice, the task of data mining, especially for some large companies, is made a lot easier by having access to a data warehouse. A primary goal of a data warehouse is to increase the “intelligence” of a decision process and the knowledge of the people involved in this process. For example, the ability of product marketing executives to look at multiple dimensions of a product’s sales performance—by region, by type of sales, by customer demographics—may enable better promotional efforts, increased production, or new decisions in product inventory and distribution. It should be noted that average companies work with averages. The superstars differentiate themselves by paying attention to the details. They may need to slice and dice the data in different ways to obtain a deeper understanding of their organization and to make possible improvements. To undertake these processes, users have to know what data exist, where they are located, and how to access them.
A data warehouse means different things to different people. Some definitions are limited to data; others refer to people, processes, software, tools, and data. One of the global definitions is the following:
The data warehouse is a collection of integrated, subject-oriented databases designed to support the decision-support functions (DSF), where each unit of data is relevant to some moment in time
.
Based on this definition, a data warehouse can be viewed as an organization’s repository of data, set up to support strategic decision making. The function of the data warehouse is to store the historical data of an organization in an integrated manner that reflects the various facets of the organization and business. The data in a warehouse are never updated but used only to respond to queries from end users who are generally decision makers. Typically, data warehouses are huge, storing billions of records. In many instances, an organization may have several local or departmental data warehouses often called data marts. A data mart is a data warehouse that has been designed to meet the needs of a specific group of users. It may be large or small, depending on the subject area.