Data Mining (3 page)
Authors: Mehmed Kantardzic

If we do not have any a priori knowledge about the target system, then structure identification becomes difficult, and we have to select the structure by trial and error. While we know a great deal about the structures of most engineering systems and industrial processes, in a vast majority of target systems where we apply data-mining techniques, these structures are totally unknown, or they are so complex that it is impossible to obtain an adequate mathematical model. Therefore, new techniques were developed for parameter identification and they are today a part of the spectra of data-mining techniques.
Finally, we can distinguish between how the terms “model” and “pattern” are interpreted in data mining. A model is a “large-scale” structure, perhaps summarizing relationships over many (sometimes all) cases, whereas a pattern is a local structure, satisfied by few cases or in a small region of a data space. It is also worth noting here that the word “pattern,” as it is used in pattern recognition, has a rather different meaning for data mining. In pattern recognition it refers to the vector of measurements characterizing a particular object, which is a point in a multidimensional data space. In data mining, a pattern is simply a local model. In this book we refer to n-dimensional vectors of data as
samples
.
1.3 DATA-MINING PROCESS
Without trying to cover all possible approaches and all different views about data mining as a discipline, let us start with one possible, sufficiently broad definition of data mining:
Data mining is a process of discovering various models, summaries, and derived values from a given collection of data.
The word “process” is very important here. Even in some professional environments there is a belief that data mining simply consists of picking and applying a computer-based tool to match the presented problem and automatically obtaining a solution. This is a misconception based on an artificial idealization of the world. There are several reasons why this is incorrect. One reason is that data mining is not simply a collection of isolated tools, each completely different from the other and waiting to be matched to the problem. A second reason lies in the notion of matching a problem to a technique. Only very rarely is a research question stated sufficiently precisely that a single and simple application of the method will suffice. In fact, what happens in practice is that data mining becomes an iterative process. One studies the data, examines it using some analytic technique, decides to look at it another way, perhaps modifying it, and then goes back to the beginning and applies another data-analysis tool, reaching either better or different results. This can go around many times; each technique is used to probe slightly different aspects of data—to ask a slightly different question of the data. What is essentially being described here is a voyage of discovery that makes modern data mining exciting. Still, data mining is not a random application of statistical and machine-learning methods and tools. It is not a random walk through the space of analytic techniques but a carefully planned and considered process of deciding what will be most useful, promising, and revealing.
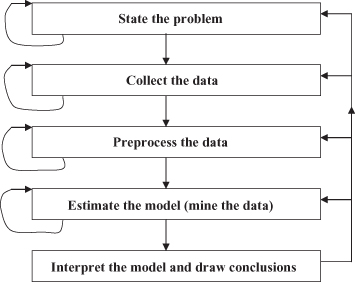
It is important to realize that the problem of discovering or estimating dependencies from data or discovering totally new data is only one part of the general experimental procedure used by scientists, engineers, and others who apply standard steps to draw conclusions from the data. The general experimental procedure adapted to data-mining problems involves the following steps:
1.
State the problem and formulate the hypothesis.
Most data-based modeling studies are performed in a particular application domain. Hence, domain-specific knowledge and experience are usually necessary in order to come up with a meaningful problem statement. Unfortunately, many application studies tend to focus on the data-mining technique at the expense of a clear problem statement. In this step, a modeler usually specifies a set of variables for the unknown dependency and, if possible, a general form of this dependency as an initial hypothesis. There may be several hypotheses formulated for a single problem at this stage. The first step requires the combined expertise of an application domain and a data-mining model. In practice, it usually means a close interaction between the data-mining expert and the application expert. In successful data-mining applications, this cooperation does not stop in the initial phase; it continues during the entire data-mining process.
2.
Collect the data.
This step is concerned with how the data are generated and collected. In general, there are two distinct possibilities. The first is when the data-generation process is under the control of an expert (modeler): this approach is known as a
designed experiment
. The second possibility is when the expert cannot influence the data-generation process: this is known as the
observational approach
. An observational setting, namely, random data generation, is assumed in most data-mining applications. Typically, the sampling distribution is completely unknown after data are collected, or it is partially and implicitly given in the data-collection procedure. It is very important, however, to understand how data collection affects its theoretical distribution, since such a priori knowledge can be very useful for modeling and, later, for the final interpretation of results. Also, it is important to make sure that the data used for estimating a model and the data used later for testing and applying a model come from the same unknown sampling distribution. If this is not the case, the estimated model cannot be successfully used in a final application of the results.
3.
Preprocess the data.
In the observational setting, data are usually “collected” from the existing databases, data warehouses, and data marts. Data preprocessing usually includes at least two common tasks:
(a)
Outlier detection (and removal)
Outliers are unusual data values that are not consistent with most observations. Commonly, outliers result from measurement errors, coding and recording errors, and, sometimes are natural, abnormal values. Such nonrepresentative samples can seriously affect the model produced later. There are two strategies for dealing with outliers:
(i)
Detect and eventually remove outliers as a part of the preprocessing phase, or
(ii)
Develop robust modeling methods that are insensitive to outliers.
(b)
Scaling, encoding, and selecting features
Data preprocessing includes several steps, such as variable scaling and different types of encoding. For example, one feature with the range [0, 1] and the other with the range [−100, 1000] will not have the same weight in the applied technique; they will also influence the final data-mining results differently. Therefore, it is recommended to scale them, and bring both features to the same weight for further analysis. Also, application-specific encoding methods usually achieve dimensionality reduction by providing a smaller number of informative features for subsequent data modeling.
These two classes of preprocessing tasks are only illustrative examples of a large spectrum of preprocessing activities in a data-mining process.
Data-preprocessing steps should not be considered as completely independent from other data-mining phases. In every iteration of the data-mining process, all activities, together, could define new and improved data sets for subsequent iterations. Generally, a good preprocessing method provides an optimal representation for a data-mining technique by incorporating a priori knowledge in the form of application-specific scaling and encoding. More about these techniques and the preprocessing phase in general will be given in Chapters 2 and 3, where we have functionally divided preprocessing and its corresponding techniques into two subphases: data preparation and data-dimensionality reduction.
4.
Estimate the model.
The selection and implementation of the appropriate data-mining technique is the main task in this phase. This process is not straightforward; usually, in practice, the implementation is based on several models, and selecting the best one is an additional task. The basic principles of learning and discovery from data are given in Chapter 4 of this book. Later, Chapters 5 through 13 explain and analyze specific techniques that are applied to perform a successful learning process from data and to develop an appropriate model.
5.
Interpret the model and draw conclusions.
In most cases, data-mining models should help in decision making. Hence, such models need to be interpretable in order to be useful because humans are not likely to base their decisions on complex “black-box” models. Note that the goals of accuracy of the model and accuracy of its interpretation are somewhat contradictory. Usually, simple models are more interpretable, but they are also less accurate. Modern data-mining methods are expected to yield highly accurate results using high-dimensional models. The problem of interpreting these models (also very important) is considered a separate task, with specific techniques to validate the results. A user does not want hundreds of pages of numerical results. He does not understand them; he cannot summarize, interpret, and use them for successful decision making.
Even though the focus of this book is on steps 3 and 4 in the data-mining process, we have to understand that they are just two steps in a more complex process. All phases, separately, and the entire data-mining process, as a whole, are highly iterative, as shown in Figure
1.2
. A good understanding of the whole process is important for any successful application. No matter how powerful the data-mining method used in step 4 is, the resulting model will not be valid if the data are not collected and preprocessed correctly, or if the problem formulation is not meaningful.
Figure 1.2.
The data-mining process.
1.4 LARGE DATA SETS
As we enter the age of digital information, the problem of data overload looms ominously ahead. Our ability to analyze and understand massive
data sets
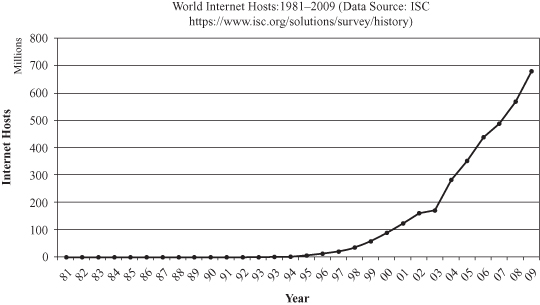
, as we call large data, is far behind our ability to gather and store the data. Recent advances in computing, communications, and digital storage technologies, together with the development of high-throughput data-acquisition technologies, have made it possible to gather and store incredible volumes of data. Large databases of digital information are ubiquitous. Data from the neighborhood store’s checkout register, your bank’s credit card authorization device, records in your doctor’s office, patterns in your telephone calls, and many more applications generate streams of digital records archived in huge business databases. Complex distributed computer systems, communication networks, and power systems, for example, are equipped with sensors and measurement devices that gather and store a variety of data for use in monitoring, controlling, and improving their operations. Scientists are at the higher end of today’s data-collection machinery, using data from different sources—from remote-sensing platforms to microscope probing of cell details. Scientific instruments can easily generate terabytes of data in a short period of time and store them in the computer. One example is the hundreds of terabytes of DNA, protein-sequence, and gene-expression data that biological science researchers have gathered at steadily increasing rates. The information age, with the expansion of the Internet, has caused an exponential growth in information sources and also in information-storage units. An illustrative example is given in Figure
1.3
, where we can see a dramatic increase in Internet hosts in recent years; these numbers are directly proportional to the amount of data stored on the Internet.
Figure 1.3.
Growth of Internet hosts.
It is estimated that the digital universe consumed approximately 281 exabytes in 2007, and it is projected to be 10 times that size by 2011. (One exabyte is ∼10
18
bytes or 1,000,000 terabytes). Inexpensive digital and video cameras have made available huge archives of images and videos. The prevalence of Radio Frequency ID (RFID) tags or transponders due to their low cost and small size has resulted in the deployment of millions of sensors that transmit data regularly. E-mails, blogs, transaction data, and billions of Web pages create terabytes of new data every day.