In the Beginning Was Information (23 page)
Read In the Beginning Was Information Online
Authors: Werner Gitt
Tags: #RELIGION / Religion & Science, #SCIENCE / Study & Teaching

iii) In the simplest symmetrical case where there are only two different symbols (e.g., "0" and "1") which occur equally frequently (
p
1
= 0.5 and
p
2
= 0.5), the information content
I
of such a symbol will be exactly one bit.
According to the laws of probability, the probability of two independent events (e.g., throwing two dice) is equal to the product of the single probabilities:
(1)
p
=
p
1
x
p
2
The first requirement (i)
I
(
p
) =
I
(
p
1
x
p
2
) =
I
(
p
1
) +
I
(
p
2
) is met mathematically when the logarithm of equation (1) is taken. The second requirement (ii) is satisfied when
p
1
and
p
2
are replaced by their reciprocals 1/
p
1
and 1/
p
2
:
(2)
I
(
p
1
x
p
2
) = log(1/
p
1
) + log(1/
p
2
).
As yet, the base
b
of the logarithms in equation (2) entails the question of measure and is established by the third requirement (iii):
(3)
I
= log
b
(1/
p
) = log
b
(1/0.5) = log
b
2 = 1 bit
It follows from log
b
2 = 1 that the base
b
= 2 (so we may regard it as a binary logarithm, as notation we use log2 = lb; giving lb
x
= (log
x
)/(log 2); log
x
means the common logarithm that employs the base 10: log
x
= log10
x
). We can now deduce that the definition of the information content
I
of one
single
symbol with probability
p
of appearing, is
(4)
I
(
p
) = lb(1/
p
) = - lb
p
≥ 0.
According to Shannon’s definition, the information content of a single message (whether it is one symbol, one syllable, or one word) is a measure of the uncertainty of its reception. Probabilities can only have values ranging from 0 to 1 (0 ≤
p
≤1), and it thus follows from equation (4) that
I
(
p
) ≥ 0, meaning that the numerical value of information content is always positive. The information content of a number of messages (e.g., symbols) is then given by requirement (i) in terms of the sum of the values for single messages
(5)
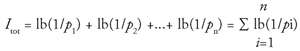 |
As shown in [G7], equation (5) can be reduced to the following mathematically equivalent relationship:
(6)
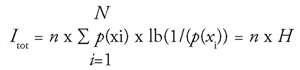 |
Note the difference between
n
and
N
used with the summation sign ∑. In equation (5) the summation is taken over all
n
members of the received sequence of signs, but in (6) it is summed for the number of symbols
N
in the set of available symbols.
Explanation of the variables used in the formulas:
n
= the number of symbols in a given (long) sequence (e.g., the total number of letters in a book)
N
= number of different symbols available
(e.g.:
N
= 2 for the binary symbols 0 and 1, and for the Morse code symbols and –
N
= 26 for the Latin alphabet: A, B, C, …, Z
N
= 26 x 26 = 676 for bigrams using the Latin alphabet: AA, AB, AC, …, ZZ
N
= 4 for the genetic code: A, C, G, T
x
i
;
i
= 1 to
N
, sequence of the
N
different symbols
I
tot
= information content of an entire sequence of symbols
H
= the average information content of one symbol (or of a bigram, or trigram; see Table 4); the average value of the information content of one single symbol taken over a long sequence or even over the entire language (counted for many books from various types of literature).
Shannon’s equations (6) and (8) used to find the total (statistical!) information content of a sequence of symbols (e.g., a sentence, a chapter, or a book), consist of two essentially different parts:
a) the factor n,
which indicates that the information content is directly proportional to the number of symbols used. This is totally inadequate for describing real information. If, for example, somebody uses a spate of words without really saying anything, then Shannon would rate the information content as very large, because of the great number of letters employed. On the other hand, if someone who is an expert, expresses the actual meanings concisely, his "message" is accorded a very small information content.
b)
the variable H
, expressed in equation (6) as a summation over the available set of elementary symbols.
H
refers to the different frequency distributions of the letters and thus describes a general characteristic of the language being used. If two languages A and B use the same alphabet (e.g., the Latin alphabet), then
H
will be larger for A when the letters are more evenly distributed, i.e., are closer to an equal distribution. When all symbols occur with exactly the same frequency, then
H
= lb
N
will be a maximum.
An equal distribution is an exceptional case: We consider the case where all symbols can occur with equal probability, e.g., when zeros and ones appear with the same frequency as for random binary signals. The probability that two given symbols (e.g., G, G) appear directly one after the other, is
p
2
; but the information content
I
is doubled because of the logarithmic relationship. The information content of an arbitrary long sequence of symbols (n symbols) from an available supply (e.g., the alphabet) when the probability of all symbols is identical, i.e.:
p
1
=
p
2
= ... =
p
N
=
p
, is found from equation (5) to be:
(7)
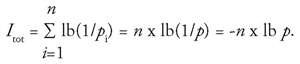 |
If all
N
symbols may occur with the same frequency, then the probability is
p
= 1/
N
. If this value is substituted in equation (7), we have the important equation:
(8)
I
tot
=
n
x lb
N
=
n
x
H
.
2. The average information content of one single symbol in a sequence:
If the symbols of a long sequence occur with differing probabilities (e.g., the sequence of letters in an English text), then we are interested in the average information content of each symbol in this sequence, or the average in the case of the language itself. In other words: What is the average information content in this case with relation to the average uncertainty of a single symbol?
To compute the average information content per symbol
I
ave
, we have to divide the number given by equation (6) by the number of symbols concerned:
(9)
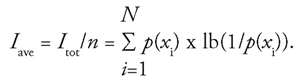 |
When equation (9) is evaluated for the frequencies of the letters occurring in English, the values shown in Table 1 are obtained. The average information content of one letter is
I
ave
= 4.045 77. The corresponding value for German is
I
ave
= 4.112 95.
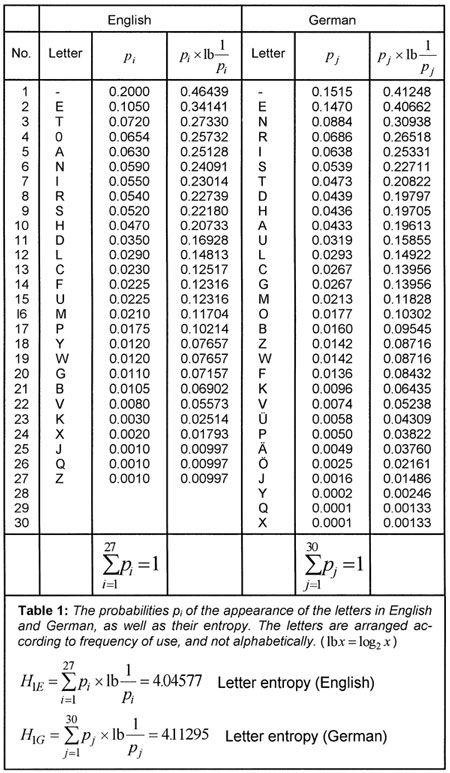 |
The average
I
ave
(
x
) which can be computed from equation (9) thus is the arithmetic mean of the all the single values
I
(
x
). The average information content of every symbol is given in Table 1 for two different symbol systems (the English and German alphabets); for the sake of simplicity
i
is used instead of
I
ave
. The average information content for each symbol
I
ave
(
x
) ≡
i
is the same as the expectation value
[22]
of the information content of one symbol in a long sequence. This quantity is also known as the entropy
[23]
H
of the source of the message or of the employed language (
I
ave
≡
i
≡
H
). Equation (9) is a fundamental expression in Shannon’s theory. It can be interpreted in various ways: