Pro Oracle Database 11g Administration (23 page)

CHAPTER 5 ■ MANAGING CONTROL FILES AND ONLINE REDO LOGS
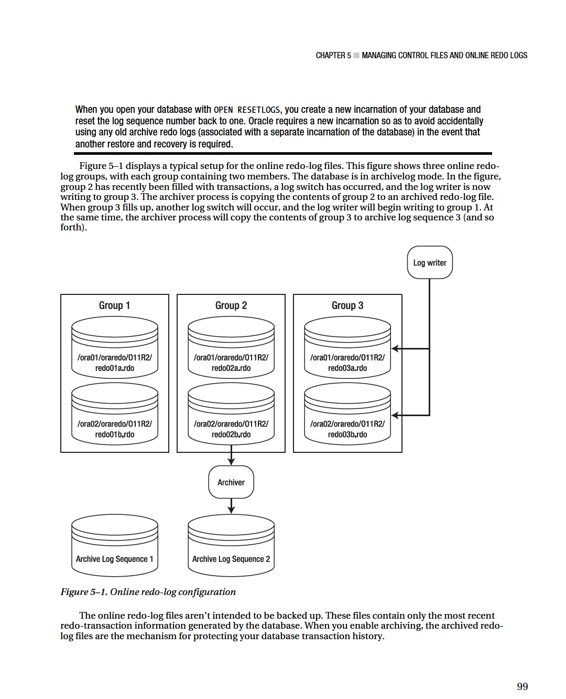
The contents of the current online redo-log files aren’t archived until a log switch occurs. This means that if you lose all members of the current online redo-log file, you lose transactions. Listed next are several mechanisms you can implement to minimize the chance of failure with the online redo-log files:
• Multiplex groups to have multiple members.
• Never allow two members of the same group to share the same controller.
• Never put two members of the same group on the same physical disk.
• Ensure that OS file permissions are set appropriately.
• Use physical storage devices that are redundant (that is, RAID).
• Appropriately size the log files so that they switch and are archived at regular intervals.
• Set the ARCHIVE_LAG_TARGET initialization parameter to ensure that the online redo logs are switched at regular intervals.
■
Note
The only tool provided by Oracle that can protect you and preserve all committed transactions in the event you lose all members of the current online redo-log group is Oracle Data Guard implemented in Maximum Protection Mode. For more details, see the Data Guard Concepts and Administration guide, available on Oracle’s Oracle Technology Network (OTN) website.
The online redo-log files are never backed up by an RMAN backup or by a user-managed hot backup. If you did back up the online redo-log files, it would be meaningless to restore them. The online redo-log files contain the latest redo generated by the database. You wouldn’t want to overwrite them from a backup with old redo information. For a database in archivelog mode, the online redo-log files contain the most recently generated transactions that are required to perform a complete recovery.
Displaying Online Redo-Log Information
Use the V$LOG and V$LOGFILE views to display information about online redo-log groups and corresponding members:
select a.group#,a.member,b.status,b.archived,bytes/1024/1024 mbytes
from v$logfile a, v$log b
where a.group# = b.group#
order by 1,2;
Here is some sample output:
GROUP# MEMBER STATUS ARCHIVED MBYTES
-------- ----------------------------------- ---------- -------- ---------
1 /ora01/oraredo/O11R2/redo01a.rdo INACTIVE YES 100
1 /ora02/oraredo/O11R2/redo01b.rdo INACTIVE YES 100
2 /ora01/oraredo/O11R2/redo02a.rdo CURRENT NO 100
2 /ora02/oraredo/O11R2/redo02b.rdo CURRENT NO 100
100
CHAPTER 5 ■ MANAGING CONTROL FILES AND ONLINE REDO LOGS
When you’re diagnosing online redo-log issues, the V$LOG and V$LOGFILE views are particularly helpful. You can query these views while the database is mounted or open. Table 5–1 briefly describes each view.
Table 5–1.
Useful Views Related to Online Redo Logs
View Description
V$LOG
Displays the online redo-log group information stored in the control file V$LOGFILE
Displays online redo-log file member information
The STATUS column of the V$LOG view is particularly useful when you’re working with online redo-logs groups. Table 5–2 describes each status and meaning for the V$LOG view.
Table 5–2.
Status for Online Redo-Log Groups in the V$LOG View
Status Meaning
CURRENT
The log group is currently being written to by the log writer.
ACTIVE
The log group is required for crash recovery and may or may not have been archived.
CLEARING
The log group is being cleared out by an ALTER DATABASE CLEAR LOGFILE
command.
CLEARING_CURRENT
The current log group is being cleared of a closed thread.
INACTIVE
The log group isn’t needed for crash recovery and may or may not have been archived.
UNUSED
The log group has never been written to; it was recently created.
The STATUS column of the V$LOGFILE view also contains useful information. This view contains information about each physical online redo-log file member of a log group. Table 5–3 provides descriptions of the status of each log-file member.
Table 5–3.
Status for Online Redo-Log File Members in the V$LOGFILE View
Status Meaning
INVALID
The log-file member is inaccessible or has been recently created.
DELETED
The log-file member is no longer in use.
STALE
The log-file member’s contents aren’t complete.
NULL
The log-file member is being used by the database.
101
CHAPTER 5 ■ MANAGING CONTROL FILES AND ONLINE REDO LOGS
It’s important to differentiate between the STATUS column in V$LOG and the STATUS column in V$LOGFILE. The STATUS column in V$LOG reflects the status of the log group. The STATUS column in V$LOGFILE reports the status of the physical online redo-log file member. Refer to these tables when diagnosing issues with your online redo logs.
Determining the Optimal Size of Online Redo-Log Groups
Try to size the online redo logs so they switch anywhere from two to six times per hour. The V$LOG_HISTORY contains a history of how frequently the online redo logs have switched. Execute this query to view the number of log switches per hour:
select count(*)
,to_char(first_time,'YYYY:MM:DD:HH24')
from v$log_history
group by to_char(first_time,'YYYY:MM:DD:HH24')
order by 2;
Here’s a snippet of the output:
COUNT(*) TO_CHAR(FIRST
---------- -------------
1 2010:03:23:20
2 2010:03:23:22
19 2010:03:23:23
17 2010:03:24:00
25 2010:03:24:01
35 2010:03:24:02
23 2010:03:24:03
5 2010:03:24:04
11 2010:03:24:05
2 2010:03:24:06
From the previous output, you can see that a lot of redo generation occurred on March 24 from about midnight to 3:00 a.m. This could be due to a nightly batch job or users in different time zones updating data. For this database, the size of the online redo logs should be increased. You should try to size the online redo logs to accommodate peak transaction loads on the database.
The V$LOG_HISTORY derives its data from the control file. Each time there is a log switch, an entry is recorded in this view that details information, such as the time of the switch and the system change number (SCN). As mentioned earlier, a general rule of thumb is that you should size your online redo-log files so that they switch about two to six times per hour. You don’t want them switching too often because there is overhead with the log switch. Oracle initiates a checkpoint as part of a log switch.
During a checkpoint, the database-writer background process writes modified (also referred to as
dirty
) blocks to disk, which is resource-intensive.
On the other hand, you don’t want online redo-log files to never switch, because the current online redo log contains transactions that you may need in the event of a recovery. If a disaster causes a media failure in your current online redo log, you can lose those transactions that haven’t been archived yet.
102
CHAPTER 5 ■ MANAGING CONTROL FILES AND ONLINE REDO LOGS
■
Tip
Use the ARCHIVE_LAG_TARGET initialization parameter to set a maximum amount of time (in seconds) between log switches. A typical setting for this parameter is 1800 seconds (30 minutes). A value of 0 (default) disables this feature. This parameter is commonly used in Oracle Data Guard environments to force log switches after the specified amount of time elapses.
You can also query the OPTIMAL_LOGFILE_SIZE column from the V$INSTANCE_RECOVERY view to determine if your online redo-log files have been sized correctly:
SQL> select optimal_logfile_size from v$instance_recovery;
Here is some sample output:
OPTIMAL_LOGFILE_SIZE
--------------------
349
This reports the redo-log file size (in megabytes) that is considered optimal based on the initialization parameter setting of FAST_START_MTTR_TARGET. Oracle recommends you configure all online redo logs to be at least the value of OPTIMAL_LOGFILE_SIZE. However, when sizing your online redo logs, you must take into consideration information about your environment (such as the frequency of the switches).
Determining the Optimal Number of Redo-Log Groups
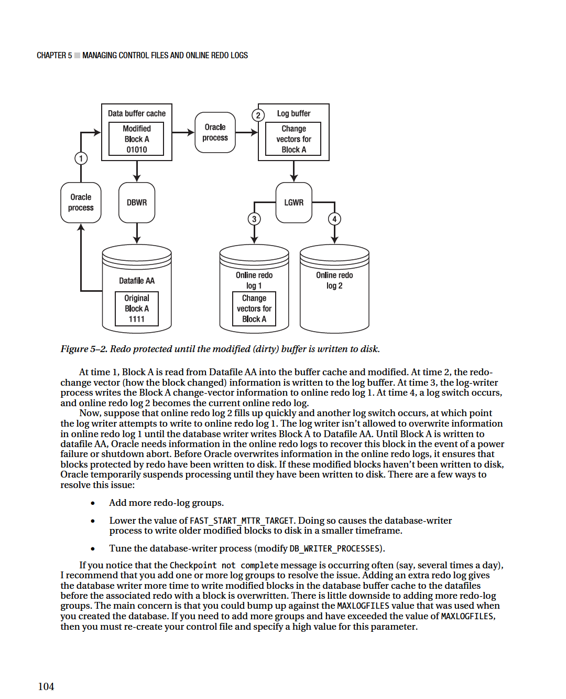
Oracle requires at least two redo-log groups to function. But having just two groups sometimes isn’t enough. To understand why two groups may not be enough, remember that every time a log switch occurs, it initiates a checkpoint. As part of a checkpoint, the database writer writes all modified (dirty) blocks from the system global area (SGA) to the datafiles on disk. Also recall that the online redo logs are written to in a round-robin fashion, and eventually the information in a given log is overwritten. Before the log writer can begin to overwrite information in an online redo log, all modified blocks in the SGA associated with the redo log must first be written to a datafile. If all modified blocks haven’t been written to the datafiles, you see this message in the alert.log file:
Thread 1 cannot allocate new log, sequence
Checkpoint not complete
Another way to explain this issue is that Oracle needs to store in the online redo logs any information that would be required to perform a crash recovery. To help visualize this, see Figure 5–2.
103
CHAPTER 5 ■ MANAGING CONTROL FILES AND ONLINE REDO LOGS
If adding more redo-log groups doesn’t resolve the issue, you should carefully consider lowering the value of FAST_START_MTTR_TARGET. When you lower this value, you can potentially see more I/O because the database-writer process is more actively writing modified blocks to datafiles. Ideally, it would be nice to verify the impact of modifying FAST_START_MTTR_TARGET in a test environment before making the change in production. You can modify this parameter while your instance is up; this means you can quickly modify it back to its original setting if there are unforeseen side effects.
Finally, consider increasing the value of the DB_WRITER_PROCESSES parameter. Carefully analyze the impact of modifying this parameter in a test environment before you apply it to production. This value requires that you stop and start your database; so, if there are adverse effects, it requires downtime to set this value back to the original setting.
Adding Online Redo-Log Groups
If you determine that you need to add an online redo-log group, use the ADD LOGFILE GROUP statement.
In this example, the database already contains four online redo-log groups that are sized at 500M each.
An additional log group is added that has two members and is sized at 500MB: alter database add logfile group 5
('/ora01/oraredo/O11R2/redo05a.rdo',
'/ora02/oraredo/O11R2/redo05b.rdo') SIZE 500M;
In this scenario, I highly recommend that the log group you add be the same size and have the same number of members as the existing online redo logs. If the newly added group doesn’t have the same physical characteristics as the existing groups, it’s harder to accurately determine performance issues with the online redo-log groups.
For example, if you have two log groups sized at 20MB, and you add a new log group sized at 200MB, this is very likely to produce the Checkpoint not complete issue described in the previous section. This is because flushing all modified blocks from the SGA that are protected by the redo in a 200MB log file can potentially take much longer than flushing modified blocks from the SGA that are protected by a 20MB
redo-log file.
Resizing Online Redo-Log Groups
You may need to change the size of your online redo logs (see also the section “Determining the Optimal Size of Online Redo-Log Groups” earlier in this chapter). You can’t directly modify the size of an existing online redo log (as you can a datafile). To resize an online redo log, you have to first add online redo-log groups that contain the size you want, and then drop the online redo logs that are the old size.