XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (113 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

.
Values can be labeled as
xs:untypedAtomic
even when they come from a document that has been validated against a schema, if the validation rules in the schema caused that part of the document to be skipped. It will also happen when an element or attribute declaration in the schema does not define a type, or when the type is given as
xs:anyType
,
xs:anySimpleType
, or
xs:anyAtomicType
. This situation can arise with documents that are part rigid structure, part free-form.
Although untyped values arise most commonly when you extract the value of an unvalidated node in a source document, you can also construct an untyped value explicitly, in the same way as any other atomic value, by using a constructor function or cast. For example, the function call xs:untypedAtomic(@date)
xs:untypedAtomic(@date) extracts the value of the
extracts the value of the
@date
attribute, and returns an untyped value regardless whether the original attribute was labeled as a date, as a string, or as something else. This technique can be useful if you need to process data that might or might not have been validated, or if you want to exploit the chameleon nature of
xs:untypedAtomic
data by using the value both as a string and as a date.
xs:NMTOKENS, xs:IDREFS, and xs:ENTITIES
This section of the chapter is about atomic types, but it would not be complete without mentioning the three built-in types defined in XML Schema that are not atomic, namely
xs:NMTOKENS
,
xs:IDREFS
, and
xs:ENTITIES
. These all reflect attribute types that were defined in DTDs, and are carried forward into XML Schema to make transition from DTDs to schemas as painless as possible.
In the sense of XML Schema, these are list types rather than atomic types. XML Schema distinguishes complex types, which can contain elements and attributes, from simple types which can't. Simple types can be defined in three ways: directly by restricting an existing simple type, by list, which allows a list of values drawn from a simple type, or by union, which allows a choice of values from two or more different simple types. But when it comes down to actual values, an instance of a simple type is either a single atomic value or a list of atomic values. Single atomic values correspond directly to atomic values in the XPath data model, as described in the previous chapter, while lists of atomic values correspond to sequences.
If an element or attribute is defined in the schema to have a list type such as
xs:NMTOKENS
, then after validation the element or attribute node will have a type annotation of
xs:NMTOKENS
. But when an XPath expression reads the content of the element or attribute node (a process called atomization), the result is not a single value of type
xs:NMTOKENS
, but a sequence of values, each of which is an atomic value labeled as an
xs:NMTOKEN
.
For example, you can test an attribute to see whether it is of type
xs:NMTOKENS
like this:
if (@A instance of attribute(*, xs:NMTOKENS)) …
or you can test its value to see if it is a sequence of
xs:NMTOKEN
values like this:
if (data(@A) instance of xs:NMTOKEN * ) …
What you cannot do is to test the attribute node against the sequence typexs:NMTOKEN*, or the value contained in the attribute against the list typexs:NMTOKENS. Both will give you syntax errors if you attempt them. For more information on using theinstance ofoperator to test the type of a value, see Chapter 11.
Schema Types and XPath Types
The preceding discussion about list types demonstrates that while the XPath type system is based on XML Schema, the types defined in XML Schema are not exactly the same thing as the types that XPath values can take. This is best illustrated by looking at the two type hierarchies and seeing how they compare. The type hierarchy in XML Schema is shown in
Figure 5-4
.
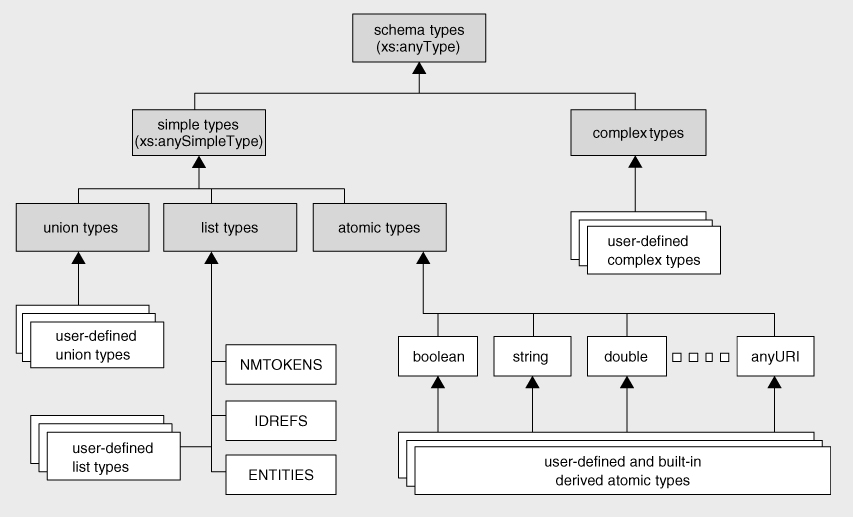
This type hierarchy contains all the types that can be used as type annotations on nodes. The boxes that are shown unshaded are concrete types, so they can be used directly; the shaded boxes are abstract types, which can only be used via their subtypes. Some of the abstract types are named, which means you can refer to them in an XPath expression (for example you can writeelement(*
,
xs:anySimpleType)which will match any element whose type annotation shows that its type is a simple type). Others are unnamed, which means you cannot refer to them directly.