XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (144 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

xmlns:xsl=“http://www.w3.org/1999/XSL/Transform”
xmlns:xs=“http://www.w3.org/2001/XMLSchema”
exclude-result-prefixes=“xs”
version=“2.0”
>
as=“xs:integer”/>
select=“$list[position()!=1]”/>
Output
The output gives the text of the longest speech in this scene. It starts like this:
Our version of AltovaXML 2008 gave the wrong answer on this stylesheet. Altova tell us there's a fix in the next release.
Note that this is taking advantage of several new features of XSLT 2.0. The template uses as=“element(SPEECH)”
as=“element(SPEECH)” can be used even when there is no schema. The example could have been rewritten to make much heavier use of XSLT 2.0 features; for example, it could have been written usingifexpression. The result would have occupied fewer lines of code, but it would not necessarily have been any more readable or more efficient.
can be used even when there is no schema. The example could have been rewritten to make much heavier use of XSLT 2.0 features; for example, it could have been written usingifexpression. The result would have occupied fewer lines of code, but it would not necessarily have been any more readable or more efficient.
There is another solution to this problem that may be more appropriate depending on the circumstances. This involves sorting the node-set, and taking the first or last element. It goes like this:
In principle, the recursive solution should be faster, because it only looks at each node once, whereas sorting all the values requires more work than is strictly necessary to find the largest. In practice, though, it rather depends on how efficiently recursion is implemented in the particular processor.
Another case where recursion has traditionally been useful is processing of a list presented in the form of a string containing a list of tokens. In XSLT 2.0, most such problems can be tackled much more conveniently using the XPath 2.0
tokenize()
function, which breaks a string into a sequence by using regular expressions, or by using the
Example: Using Recursion to Process a Sequence of Strings
Suppose that you want to find all the lines within a play that contain the phrase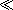 A and B
A and B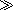 , where A and B are both names of characters in the play.
, where A and B are both names of characters in the play.
Source
There is only one line in the whole of
Othello
that meets these criteria. So you will need to run the stylesheet against the full play,
othello.xml
.
Stylesheet
The stylesheet
naming-lines.xsl
starts by declaring a global variable whose value is the set of names of the characters in the play, with duplicates removed and case normalized for efficiency:
xmlns:xsl=“http://www.w3.org/1999/XSL/Transform”
xmlns:xs=“http://www.w3.org/2001/XMLSchema”
xmlns:local=“local-functions.uri”
exclude-result-prefixes=“xs local”
version=“2.0”
>
select=“for $w in distinct-values(//SPEAKER) return upper-case($w)”/>
We'll write a function that splits a line into its words. This was hard work in XSLT 1.0, but it is now much easier.
The next step is a function that tests whether a given word is the name of a character in the play:
This way of doing case-independent matching isn't really recommended, it's better to use a collation designed for the purpose, but it works with this data. Note that we are relying on the “existential” properties of the=operator: that is, the fact that it compares the word on the left with every string in the
$speakers
sequence.
Now I'll write a named template that processes a sequence of words, and looks for the phraseA and Bwhere A and B are both the names of characters.
lower-case($words[2]) = ‘and’ and
local:is-character($words[3])”>
select=“$words[position() gt 1]”/>
Then comes the “main program,” the template rule that matches the root node. This simply calls the named template for each
Output
The output is simply: