CSS: The Definitive Guide, 3rd Edition (6 page)
Read CSS: The Definitive Guide, 3rd Edition Online
Authors: Eric A. Meyer
Tags: #COMPUTERS / Web / Page Design

When it comes to both class and ID selectors, what
you're really doing is selecting values of attributes. The syntax used in the previous
two sections is particular to HTML, SVG, and MathML documents (as of this writing). In
other markup languages, these class and ID selectors may not be available. To address
this situation, CSS2 introduced
attribute selectors
,
which can be used to select elements based on
their attributes and the values of those attributes. There are four types of attribute
selectors.
Attribute selectors are supported by Safari, Opera, and all Gecko-based browsers,
but not by Internet Explorer up through IE5/Mac and IE6/Win. IE7 fully supports all
CSS2.1 attribute selectors, as well as a few CSS3 attribute selectors, which are
covered in this section.
If you want to select elements that have a certain attribute, regardless of that
attribute's value, you can use a simple attribute selector. For example, to select
allh1elements that have aclassattribute with any value and make their text
silver, write:
h1[class] {color: silver;}
So, given the following markup:
Hello
Serenity
Fooling
you get the result shown in
Figure
2-10
.

Figure 2-10. Selecting elements based on their attributes
This strategy is very useful in XML documents, as XML languages tend to have
element and attribute names that are very specific to their purpose. Consider an XML
language that is used to describe planets of the solar system (we'll call it
PlanetML). If you want to select allplanetelements with amoonsattribute and make them
boldface, thus calling attention to any planet that has moons, you would write:
planet[moons] {font-weight: bold;}
This would cause the text of the second and third elements in the following markup
fragment to be boldfaced, but not the first:
Venus Earth Mars
In HTML documents, you can use this feature in a number of creative ways. For
example, you could style all images that have analtattribute, thus highlighting those images that are correctly formed:
img[alt] {border: 3px solid red;}
(This particular example is useful more for diagnostic purposes—that is,
determining whether images are indeed correctly formed—than for design purposes.)
If you wanted to boldface any element that includestitleinformation, which most browsers display as a "tool tip" when a
cursor hovers over the element, you could write:
*[title] {font-weight: bold;}
Similarly, you could style only those anchors (aelements) that have anhrefattribute.
It is also possible to select based on the presence of more than one attribute.
You do this simply by chaining the attribute selectors together. For example, to
boldface the text of any HTML hyperlink that has both anhrefand atitleattribute, you
would write:
a[href][title] {font-weight: bold;}
This would boldface the first link in the following markup, but not the second or
third:
W3C
Standards Info
dead.letter
In addition to
selecting elements with attributes, you can further narrow the selection process to
encompass only those elements whose attributes are a certain value. For example,
let's say you want to boldface any hyperlink that points to a certain document on the
web server. This would look something like:
a[href="http://www.css-discuss.org/about.html"] {font-weight: bold;}
Any attribute and value combination can be specified for any element. However, if
that exact combination does not appear in the document, then the selector won't match
anything. Again, XML languages can benefit from this approach to styling. Let's
return to our PlanetML example. Suppose you want to select only thoseplanetelements that have a value of1for the attributemoons:
planet[moons="1"] {font-weight: bold;}
This would boldface the text of the second element in the following markup
fragment, but not the first or third:
Venus Earth Mars
As with attribute selection, you can chain together multiple attribute-value
selectors to select a single document. For example, to double the size of the text of
any HTML hyperlink that has both anhrefwith a
value of
http://www.w3.org/
and atitleattribute with a value ofW3C, you would write:
Home
a[][title="W3C Home"] {font-size: 200%;}
This would double the text size of the first link in the following markup, but not
the second or third:
W3C
title="Web Standards Organization">Standards Info
dead.link
The results are shown in
Figure 2-11
.

Figure 2-11. Selecting elements based on attributes and their values
Note that this format requires an exact match for the attribute's value. Matching
becomes an issue when the form encounters values that can in turn contain a
space-separated list of values (e.g., the HTML attributeclass). For example, consider the following markup fragment:
Mercury
The only way to match this element based on its exact attribute value is to write:
planet[type="barren rocky"] {font-weight: bold;}
If you were to writeplanet[type="barren"], the
rule would not match the example markup and thus would fail. This is true even for
theclassattribute in HTML. Consider the
following:
When handling plutonium, care must be taken to
avoid the formation of a critical mass.
To select this element based on its exact attribute value, you would have to
write:
p[class="urgent warning"] {font-weight: bold;}
This is
not
equivalent to the dot-class notation covered
earlier, as we will discuss in the next section. Instead, it selects anypelement whoseclassattribute has
exactly
the valueurgent, with the words in that order and a single space between them.
warning
It's effectively an exact string match.
Also, be aware that ID selectors and attribute selectors that target theidattribute are not precisely the same. In other words,
there is a subtle but crucial difference betweenh1#page-titleandh1[id="page-title"]. This difference is explained in the next
chapter.
For any
attribute that accepts a space-separated list of words, it is possible to select
based on the presence of any one of those words. The classic example in HTML is theclassattribute, which can accept one or more
words as its value. Consider our usual example text:
When handling plutonium, care must be taken to
avoid the formation of a critical mass.
Let's say you want to select elements whoseclassattribute contains the wordwarning. You can do this with an attribute selector:
p[class~="warning"] {font-weight: bold;}
Note the presence of the tilde (~) in the
selector. It is the key to selection based on the presence of a space-separated word
within the attribute's value. If you omit the tilde, you would have an exact-value
matching requirement, as discussed in the previous section.
This selector construct is equivalent to the dot-class notation discussed earlier.
Thus,p.warningandp[class~="warning"]are equivalent when applied to HTML documents.
Here's an example that is an HTML version of the "PlanetML" markup seen earlier:
Earth
To italicize all elements with the wordbarrenin theirclassattribute, you write:
span[class~="barren"] {font-style: italic;}
This rule's selector will match the first two elements in the example markup and
thus italicize their text, as shown in
Figure
2-12
. This is the same result we would expect from writingspan.barren {font-style: italic;}.
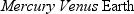
Figure 2-12. Selecting elements based on portions of attribute values
So why bother with the tilde-equals attribute selector in HTML? Because it can be
used for any attribute, not justclass. For
example, you might have a document that contains a number of images, only some of
which are figures. You can use a partial-value attribute selector aimed at thetitletext to select only those figures:
img[title~="Figure"] {border: 1px solid gray;}
This rule will select any image whosetitletext contains the wordFigure. Therefore, as long
as all your figures havetitletext that looks
something like "Figure 4. A bald-headed elder statesman," this rule will match those
images. For that matter, the selectorimg[title~="Figure"]will also match a title attribute with the value "How
To Figure Out Who's In Charge." Any image that does not have atitleattribute, or whosetitlevalue doesn't contain the word "Figure," won't be matched.
The even more advanced CSS Selectors module, which was released well after CSS2
was completed, contains a few more partial-value attribute selectors (or, as the
specification calls them, "
substring matching
attribute selectors
"). Since these are supported in many modern browsers,
including IE7, we'll cover them quickly in
Table 2-1
.
Table 2-1. Substring matching attribute selectors
Type | Description |
|---|---|
| Selects any element with an attribute |
| Selects any element with an attribute |
| Selects any element with an attribute |
Thus, given the following rules and markup, we would get the result shown in
Figure 2-13
.
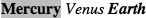
Figure 2-13. Selecting elements based on substrings within attribute values
span[class*="cloud"] {font-style: italic;}
span[class^="bar"] {background: silver;}
span[class$="y"] {font-weight: bold;}
Earth
The first of the three rules matches anyspanelement whoseclassattribute contains the
substringcloud, so both "cloudy" planets are
matched. The second rule matches anyspanelement
whoseclassattribute starts with the substringbar, so the only match is Mercury, whoseclassvalue isbarren. Venus is not matched because the
rockybarinbarrencomes later in itsclassvalue, not at the beginning. Finally, the
third rule matches anyspanelement whoseclassattribute ends with the substringy, so Mercury and Earth both are picked. Venus is again
left out in the cold, since the end of itsclassvalue is noty.
As you can imagine, there are many useful applications for such selectors. As an
example, suppose you wanted to specially style any links to the O'Reilly Media web
site. Instead of classing them all and writing styles based on that class, you could
simply write the following rule:
a[href*="oreilly.com"] {font-weight: bold;}
And, of course, you aren't confined to theclassandhrefattributes. Any
attribute is up for grabs here.title,alt,src,id... you name it, you can style based on its value or
some part thereof. The following rule draws attention to any spacer GIF in an
old-school table layout (plus any other image with the string "space" in its URL):
img[src*="space"] {border: 5px solid red;}
As of this writing, support for these substring selectors is confined to
Safari, Gecko-based browsers, Opera, and IE7/Win.