Data Mining (93 page)
Authors: Mehmed Kantardzic

Hypertext documents, usually represented as basic components on the Web, are a special type of text-based document that have hyperlinks in addition to text. They are modeled with varying levels of details, depending on the application. In the simplest model, hypertext can be regarded as directed graph (D, L) where D is the set of nodes representing documents or Web pages, and L is the set of links. Crude models may not need to include the text models at the node level, when the emphasis is on document links. More refined models will characterize some sort of joint distribution between the term distributions of a node with those in a certain neighborhood of the document in the graph.
Content-based analysis and partition of documents is a more complicated problem. Some progress has been made along these lines, and new text-mining techniques have been defined, but no standards or common theoretical background has been established in the domain. Generally, you can think of text categorization as comparing a document to other documents or to some predefined set of terms or definitions. The results of these comparisons can be presented visually within a semantic landscape in which similar documents are placed together in the semantic space and dissimilar documents are placed further apart. For example, indirect evidence often lets us build semantic connections between documents that may not even share the same terms. For example, “car” and “auto” terms co-occurring in a set of documents may lead us to believe that these terms are related. This may help us to relate documents with these terms as similar. Depending on the particular algorithm used to generate the landscape, the resulting topographic map can depict the strengths of similarities among documents in terms of Euclidean distance. This idea is analogous to the type of approach used to construct Kohonen feature maps. Given the semantic landscape, you may then extrapolate concepts represented by documents.
The automatic analysis of text information can be used for several different general purposes:
1.
to provide an overview of the contents of a large document collection and organize them in the most efficient way;
2.
to identify hidden structures between documents or groups of documents;
3.
to increase the efficiency and effectiveness of a search process to find similar or related information; and
4.
to detect duplicate information or documents in an archive.
Text mining is an emerging set of functionalities that are primarily built on text-analysis technology. Text is the most common vehicle for the formal exchange of information. The motivation for trying to automatically extract, organize, and use information from it is compelling, even if success is only partial. While traditional commercial text-retrieval systems are based on inverted text indices composed of statistics such as word occurrence per document, text mining must provide values beyond the retrieval of text indices such as keywords. Text mining is about looking for semantic patterns in text, and it may be defined as the process of analyzing text to extract interesting, nontrivial information that is useful for particular purposes.
As the most natural form of storing information is text, text mining is believed to have a commercial potential even higher than that of traditional data mining with structured data. In fact, recent studies indicate that 80% of a company’s information is contained in text documents. Text mining, however, is also a much more complex task than traditional data mining as it involves dealing with unstructured text data that are inherently ambiguous. Text mining is a multidisciplinary field involving IR, text analysis, information extraction, natural language processing, clustering, categorization, visualization, machine learning, and other methodologies already included in the data-mining “menu”; even some additional specific techniques developed lately and applied on semi-structured data can be included in this field. Market research, business-intelligence gathering, e-mail management, claim analysis, e-procurement, and automated help desk are only a few of the possible applications where text mining can be deployed successfully. The text-mining process, which is graphically represented in Figure
11.6
, consists of two phases:
- text refining
, which transforms free-form text documents into a chosen intermediate form (IF), and - knowledge distillation
, which deduces patterns or knowledge from an IF.
Figure 11.6.
A text-mining framework.
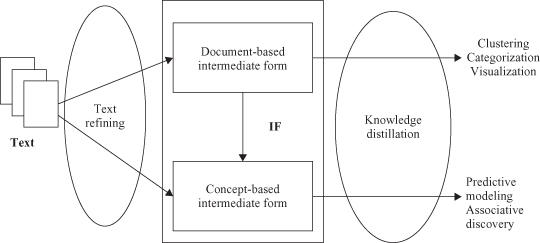
An IF can be semi-structured, such as a conceptual-graph representation, or structured, such as a relational-data representation. IFs with varying degrees of complexity are suitable for different mining purposes. They can be classified as
document-based,
wherein each entity represents a document, or
concept-based
, wherein each entity represents an object or concept of interests in a specific domain. Mining a document-based IF deduces patterns and relationships across documents. Document clustering, visualization, and categorization are examples of mining from document-based IFs.
For a fine-grained, domain-specific, knowledge-discovery task, it is necessary to perform a semantic analysis and derive a sufficiently rich representation to capture the relationship between objects or concepts described in the document. Mining a concept-based IF derives patterns and relationships across objects and concepts. These semantic-analysis methods are computationally expensive, and it is a challenge to make them more efficient and scalable for very large text corpora. Text-mining operations such as predictive modeling and association discovery fall in this category. A document-based IF can be transformed into a concept-based IF by realigning or extracting the relevant information according to the objects of interests in a specific domain. It follows that a document-based IF is usually domain-independent and a concept-based is a domain-dependent representation.
Text-refining and knowledge-distillation functions as well as the IF adopted are the basis for classifying different text-mining tools and their corresponding techniques. One group of techniques, and some recently available commercial products, focuses on document organization, visualization, and navigation. Another group focuses on text-analysis functions, IR, categorization, and summarization.
An important and large subclass of these text-mining tools and techniques is based on document visualization. The general approach here is to organize documents based on their similarities and present the groups or clusters of the documents as 2-D or 3-D graphics. IBM’s Intelligent Miner and SAS Enterprise Miner are probably the most comprehensive text-mining products today. They offer a set of text-analysis tools that include tools for feature-extraction, clustering, summarization, and categorization; they also incorporate a text search engine. More examples of text-mining tools are given in Appendix A.
Domain knowledge, not used and analyzed by any currently available text-mining tool, could play an important role in the text-mining process. Specifically, domain knowledge can be used as early as in the text-refining stage to improve parsing efficiency and derive a more compact IF. Domain knowledge could also play a part in knowledge distillation to improve learning efficiency. All these ideas are still in their infancy, and we expect that the next generation of text-mining techniques and tools will improve the quality of information and knowledge discovery from text.
11.7 LATENT SEMANTIC ANALYSIS (LSA)
LSA
is a method that was originally developed to improve the accuracy and effectiveness of IR techniques by focusing on semantic meaning of words across a series of usage contexts, as opposed to using simple string-matching operations. LSA is a way of partitioning free text using a statistical model of word usage that is similar to eigenvector decomposition and factor analysis. Rather than focusing on superficial features such as word frequency, this approach provides a quantitative measure of semantic similarities among documents based on a word’s context.
Two major shortcomings to the use of term counts are synonyms and polysemes. Synonyms refer to different words that have the same or similar meanings but are entirely different words. In the case of the vector approach, no match would be found between a query using the term “altruistic” and a document using the word “benevolent” though the meanings are quite similar. On the other hand, polysemes are words that have multiple meanings. The term “bank” could mean a financial system, to rely upon, or a type of basketball shot. All of these lead to very different types of documents, which can be problematic for document comparisons.
LSA attempts to solve these problems, not with extensive dictionaries and natural language processing engines, but by using mathematical patterns within the data itself to uncover these relationships. We do this by reducing the number of dimensions used to represent a document using a mathematical matrix operation called singular value decomposition (SVD).
Let us take a look at an example data set. This very simple data set consists of five documents. We will show the dimension reduction steps of LSA on the first four documents (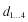 ), which will make up our training data. Then we will make distance comparisons to a fifth document (
), which will make up our training data. Then we will make distance comparisons to a fifth document (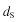 ) in our test set, using the nearest neighbor classification approach. The initial document set is:
) in our test set, using the nearest neighbor classification approach. The initial document set is:
- d
1
: A bank will protect your money. - d
2
: A guard will protect a bank. - d
3
: Your bank shot is money. - d
4
: A bank shot is lucky. - d
5
: bank guard.
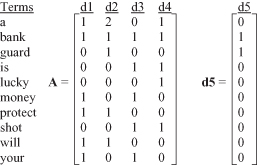
From the text data we derive a vector representation of our documents using only term counts. This vector representation could be thought of as a matrix with rows representing terms and columns representing documents. This representation may be seen in Figure
11.7
.
Figure 11.7.
Initial term counts.
The first step of LSA is to decompose the matrix representing our original data set of four documents, matrix A, using SVD as follows: A = USV
T
. The calculation of SVD is beyond the scope of this text, but there are several computing packages that will perform this operation for you (such as R or MATLAB packages). The matrices resulting from this decomposition can be seen in Figure
11.8
. The
U
and
V
T
matrices provide a vector of weights for terms and documents, respectively. Consider
V
T
, this matrix gives a new 4-D representation to each document where each document is described with a corresponding column. Each of the new dimensions is derived from the original 10 word count dimensions. For example, document 1 is now represented as follows: d
1
= −0.56x
1
+ 0.095x
2
− 0.602x
3
+ 0.562x
4
, where each x
n
represents one of the new, derived dimensions. The
S
matrix is a diagonal matrix of eigenvalues for each principal component direction.