Read Life's Ratchet: How Molecular Machines Extract Order from Chaos Online
Authors: Peter M. Hoffmann
Life's Ratchet: How Molecular Machines Extract Order from Chaos (36 page)

A detailed discussion of the entire machinery that reads, translates, repairs, duplicates, and maintains DNA would easily fill an entire book. But for the purpose of showing how molecular machines are used in almost everything our cells do, a brief overview will suffice. The DNA in our cells is rolled up—and then the rolls, in turn, are rolled up again—into compact DNA-protein structures called chromosomes. This packaging of DNA into chromosomes is performed by molecular machines.
DNA contains the information both to make proteins and to regulate the making of proteins. It does not contain the information of how to make a human—at least not directly. There is no gene for a toe or an eye. There are genes to make protein components of toes and eyes. The actual development of a human is a complicated process and involves the accurate timing of the synthesis of many proteins, their interaction, their regulation, and the movement of molecules by molecular motors. Many of these immensely complicated processes are still not well understood, although we now have a much better understanding than we did just twenty years ago. One of these well-understood processes is how a protein is made according to the instructions contained in DNA.
DNA is a double-helix molecule with a backbone made of alternating sugars (deoxyribose, which gives DNA its
D
) and phosphates. It looks like a twisted ladder. The rungs of the ladder are composed of various combinations of four nucleotide bases that constitute the DNA alphabet. The bases are adenine (A), guanine (G), thymine (T), and cytosine (C). Adenine is the same molecule that is part of adenosine triphosphate (ATP). The two sides of the double helix are complementary—this means that an A on one side always pairs up with a T on the other, and a G will always pair with a C. This specific pairing is achieved by hydrogen bonds, which are placed in such a way that, for example, T can form hydrogen bonds only with A, but not with G or C (
Figure 7.13
). Hydrogen bonds on their own are relatively weak, but the large number of hydrogen bonds fastening the two helices together gives great strength to DNA.
There are multiple advantages to DNA’s double-helix structure with complementary base pairing. For one, the redundancy provided by the pairing of bases allows cells to repair DNA when it is damaged. Second is the molecule’s ability to replicate itself, as James Watson and Francis Crick stated in their famous paper: “It has not escaped our notice that the specific pairing we have postulated immediately suggests a possible copying mechanism for the genetic material
.
” In other words, if you want to copy DNA, all you’d have to do is open up the helix and float some free bases around, and they will automatically pair up with their correct counterparts. Before long, you have made two helices out of one, both perfect copies of each other. It’s not quite that easy, as we will see, but that’s the basic idea.
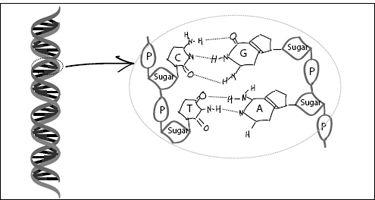
FIGURE 7.13.
DNA structure. On the left is the overall double-helix structure. The two helices are made of alternating sugar and phosphate groups, while the rungs connecting the two helices are pairs of complementary nucleotides (A [adenine], C [cytosine], T [thiamine], or G [guanine]), as seen in the magnification on the right. The specific sequence of these nucleotide letters encodes the DNA message.
The language of DNA uses three-letter words made up of four different letters (the bases A, C, T, and G). The three-letter word AAC, for example, codes for a specific amino acid in a protein. AAC happens to code for asparagine, while CUU codes for leucine. These three-letter words are called codons. The set of all three-letter words is the
genetic code
. A gene is a DNA sentence, a string of codons, which encodes a complete amino acid chain for a specific protein. For example, the KLC1 gene on chromosome 14 encodes the protein sequence for kinesin-1, our waddling motor protein.
The making of a protein proceeds through two distinct steps: transcription and translation. During transcription, the necessary information to make the protein is transcribed to another information carrier, RNA, which is a close relative of DNA. Why is this intermediate step needed? The DNA in our cells is kept safe in the cell nucleus. We do not want to cut out and remove parts of the DNA each time the cell manufactures a protein. Instead, the cell makes a temporary information carrier made of RNA, which can leave the cell nucleus and carry the information to where it is needed. This RNA information carrier is fittingly called messenger RNA (mRNA).
Thus, there are three major processes involving DNA in our cells: copying DNA when the cell divides (replication), copying DNA to RNA when a protein is to be made (transcription), and packaging DNA into chromosomes.
THE COPY MACHINERY
DNA is a very stable molecule. This is a good thing, as we do not want anything to happen to our DNA. Mistakes in our DNA can have disastrous consequences, such as the development of cancer. However, if the molecule is always curled up into a rigid structure, it would be impossible to copy or transcribe DNA. Therefore, we have to unravel, open, read, copy,
and close it up again. DNA is copied when cells divide (each cell receives a complete copy of the genetic material), and it is transcribed each time a cell needs to make a protein. Although these processes seem superficially similar, they work in completely different ways.

FIGURE 7.14.
The DNA replication machinery. Helicase untwists the helix and separates the two strands. Topoisomerase cuts and re-splices the DNA to avoid tangles. Polymerases copy the DNA and make a new double helix out of each separate strand. One of the polymerases follows the helicase, while the other two work in the opposite direction. Thus they are forced to copy the DNA in fragments, which are spliced together by ligase.
During replication, a large number of molecular machines and enzymes work together to make sure the DNA is not damaged and that a true copy of the original is produced (
Figure 7.14
). But there are several
complications. First of all, the DNA strand needs to be opened up. Second, if you have ever tried to untangle a twisted telephone cord, you can imagine that opening up a double helix can create a mess: Without proper precautions, the strands would quickly twist into a knot. To avoid a tangled mess, a molecular machine called topoisomerase snips one of the strands of DNA from time to time and passes it through the other to compensate for the final unwinding of the two strands by another molecular motor, helicase.
There is another complication: The two complementary strands of DNA are oriented in different directions. Like proteins (which have N- and C-terminals), DNA has different ends as well. The so-called 5' end has a phosphate group, and the 3' end has a sugar group. One of the strands runs from 3' to 5', while the other runs from 5' to 3'. Unfortunately, the machine that copies the DNA can only run in one direction: from 5' to 3'. This is fine for one of the two strands, because this copy machine, called DNA polymerase, can follow the machine that opens up the DNA (helicase). But the other strand points in the opposite direction. This means the copy machine on this strand has to move away from the point where the DNA is being split. What’s worse, while this is happening, more DNA is split behind the machine. How to solve this problem? Copy a small section of the DNA, move the copy machine back, copy another small section, splice the sections together using another machine (called ligase), and so on.
TWISTING THE HELIX
Although space prevents us from discussing every molecular machine in DNA replication, we will concentrate on helicase, the machine involved in untwisting (and opening) the DNA helix. These untwisting machines have two jobs: separating the complementary DNA strands, and untwisting them to get them ready for copying. Untwisting the two separated strands can lead to more twisting in the not-yet separated DNA. Topoisomerases make sure the helicase motors do not turn the DNA into a tangled knot. Structurally, helicases look like a six-sided star with a hole in the middle through which DNA passes. How is the DNA spooled through the middle? Helicases self-assemble around the DNA, most likely by opening the six-sided helicase ring, letting the DNA in, and closing up again.
The six-sided shape may help the helicase continue to do its job while the DNA curls around as it moves through the ring center.
As discussed, the rungs of the DNA ladder—the complementary bases—are held together by hydrogen bonds. Studies have shown that helicases break these bonds much faster than these bonds would break on their own. Helicases are, first of all, enzymes that speed up the splitting of the DNA double helix. Remember, any bond will eventually break on its own. Every molecule is incessantly bombarded by the molecular storm— so there is always a possibility that, by chance, the bond will receive enough energy from the thermal chaos to break. The average time this takes depends on the height of the activation barrier. Helicases lower the activation barrier for splitting the two DNA strands by manipulating the charge on DNA and therefore speeding up the unzipping process. But helicases not only facilitate splitting the DNA; they also move along DNA like a pair of scissors. As they cut, they move forward, with the motion fueled by ATP. Helicases are therefore molecular motors as well. How this motion works is still being debated: Is it a tightly coupled power stroke or a Brownian ratchet mechanism? This debate may sound familiar. Some research suggests that ATP binding weakens the helicase’s bond to DNA, allowing the helicase to move relatively freely. This would support a Brownian ratchet mechanism.
SENDING THE MESSAGE
The DNA in our cells contains all the information to make every protein needed by our bodies. To turn DNA instructions into actual proteins, the instructions have to be copied first to an RNA messenger, which transports the instructions to the factory floor, where the machines that translate DNA instructions into proteins are located. RNA is a more flexible and more ancient cousin of DNA (many people believe that life started with RNA). RNA contains a different sugar—ribose, as opposed to the deoxyribose in DNA—in its backbone, making it more flexible than DNA. Like DNA, RNA has four bases, three of which—A, C, and G—are the same as in DNA. However, the fourth base in RNA is uracil (U).
Because RNA also has four different bases, DNA language is easily transcribed into RNA language (simply replace the T with a U). This allows
RNA to play the role of messenger whenever the cell consults its DNA library to make a protein. The transcription of DNA into mRNA is accomplished by a molecular machine called RNA polymerase. This machine starts working when it encounters a specific DNA sequence, or
promoter
. The promoter marks the spot where the RNA polymerase is supposed to start transcription. Always the same, the promoter consists of two parts, ten and thirty-five base pairs before the sequence to be translated. Once the polymerase finds the promoter, it attaches to the DNA and starts making an RNA copy of the information it finds. RNA polymerase is the Swiss army knife of molecular machines. While DNA replication requires an army of enzymes and molecular machines, RNA polymerase works on its own—opening up DNA, transcribing it, moving along DNA, proofreading, and finally terminating the copying process.
The first step in transcription is to find the promoter. Unfortunately, DNA is impossibly long and coiled up. How can RNA polymerase find a specific sequence within the millions of sequences in DNA? Surprisingly, the polymerase finds its target very quickly, apparently by weakly attaching to the DNA and then sliding randomly along individual strands at a fast clip, helped by the molecular storm. Occasionally, the polymerase hops to make sure nothing gets missed. It is like shopping in a large store for a particular item: First you browse along the shelves in a linear fashion, but if it you can’t find what you are looking for, you jump to a different area of the store and try again. Combining linear searching with jumps produces an efficient search strategy.