Regenesis (11 page)
Authors: George M. Church

As we will see in
Chapter 7
, there are six industrial revolutions that were intimately connected with the development of relevant quantitative measures. Replexity may be part of the current revolution and the sense of awe we feel as we learn more about what life is.
Genome engineering will allow us to become ever more diverse, enhancing our prospects for survival. We are already extending the bodily properties of our species in several different ways. For example, we are making attempts to improve our health, lengthen our life span, and boost our immune system and disease resistance, among other things. We can also adapt to very high and very low population densities as occurs in space exploration (see
Chapter 5
and Epilogue).
The replexity (replicated complexity) involved in efforts to create a mirror world and increase diversity is vast, and exists not in the form of arbitrarily diverse or complex artifacts, like a Jackson Pollock splatter painting or a Rubik's Cube, but rather in the form of thousands of identical (or nearly identical) biomolecular devices that are themselves the survivors of the many rounds of production, change, testing, and rejection inherent in the processes of evolutionâreproduction, mutation, selection, and extinction. One of the primary errors of eugenics was the search for an optimal genetic specimen. Even if there were such a thing, it would be at risk, because one of the main lessons that we learn from nature is that species that are lowest in diversity are most vulnerable to extinction.
Consequently I am proposing a vision of maximal genomic diversity. But how is that vision connected with the minimal genome of
Chapter 2
? I will first show how the minigenome enables a huge expansion of replexity,
and then address how we might adapt and even outdo the tricks that cellular, then multicellular, and finally multi-organismal (social) systems exploit in their never-ending quest for diversity.
The ancient minimal genome, whatever its exact composition, gave rise to the totality of life forms that we see before us today. Still, there is the problem of how that genome was able to produce the complex set of amino acids, peptides, proteins, and finally the full range of living organisms that now exists. This raises the chicken-and-egg question of how life got started in the first place.
The problem is that modern cells are based on both DNA and proteins. But in order to replicate, DNA needed the proteins which act as enzymes that catalyze the whole replication process. On the other hand, the proteins themselves could not exist without DNA molecules, because those very DNA molecules contain the recipes for making the proteins. So, which came first: DNA or the proteins?
The RNA world probably came first. RNA is essentially single-stranded DNA (with uracil in place of
DNA's
thymine and an extra oxygen on each sugar). Because RNA molecules are able to act as enzymes, the prevailing theory today is that if “in the beginning there was RNA,” then RNA molecules could have catalyzed the basic reactions needed for life. Such catalytic RNA molecules are known as ribozymes (enzymes made of ribonucleic acid).
To review what we learned in high school, RNA molecules come in a variety of types, which collectively constitute the basic toolbox mechanisms of protein synthesis and cellular replication. Two types of RNA are especially important. The first is mRNA (messenger RNA), which is a single-strand RNA chain that carries the genetic information from the DNA in the cell's nucleus to the ribosomes in the cytoplasm. That information is carried in the form of a (long or short) sequence of nucleotide bases. Another crucial class of RNA is tRNA (transfer RNA), small (~75 nucleotides long), folded molecules that transport amino acids from the cytoplasm to the ribosome. These two types of RNA meet up in the ribosome, where the tRNA amino acids get strung together in the sequence dictated by the mRNA, to form a protein. (One component of a
tRNA molecule consists of a triplet of nucleotide bases that code for, or specify, a distinct amino acid [as, for example, UUU codes for the amino acid phenylalanine]. Thus you can regard tRNAs and amino acids as matched sets: each tRNA goes together with the specific amino acid encoded by its three-letter codon.)
The genetic code bridging the RNA world and the protein world was probably in place and fairly optimal before the core code protein enzymes existed. There were possibly fewer than twenty tRNA molecules and catalytic rRNA (ribosomal RNA), possibly shorter than today's rRNA molecules, plus an RNA replicase (an enzyme that catalyzes the synthesis of a complementary RNA molecule using an RNA template). The replicase might be as small as the recent 187-mer ribozyme capable of copying RNA molecules as large as 95-mers (but it cannot yet copy itself).
The smallest peptidyltransferase ribozyme (which establishes links between adjacent amino acids of a peptide) can be embedded in the tRNA structure itself. The smallest ribozyme capable of covalently attaching amino acids onto tRNAs is 45-merâa ribonucleic enzyme that's forty-five units long. This means that a minimal ribo-world (or RNA world) just ready to explode into the ribo-peptide world (or RNA-world-plus-peptides) might have been a bit bigger than 187 + 20x (75 + 45) = 2,587 nucleotides long (where 75 is the average tRNA length and 20 is the number of tRNA molecules). The next step along the path to life might have been to a polymer similar to the 113 kilo base pair-long minigenome described in
Chapter 2
.
How can we measure this evolutionary “progress”? Some say that the idea of progress is delusional and that the phrase “survival of the fittest” is tautological. But how about measuring evolutionary progress by its degree of replexity (which, remember, stands for replicated complexity)? The transition from the RNA world to life extends informational complexity to bioinformational replexity. One nearly perfect copy of any given complex structure suffices to qualify it as a candidate for replexity. Making additional copies doesn't increase replexity further, except to the extent that the copies are imperfect and hence capable of small and large impacts on selection. In
Chapter 2
, we saw that synthetically making a copy of a
genome is not as promising for changing the world, or our view of it, as is making a radically new genomeâor better yet a set of such genomes. Photographing the Mona Lisa is not as impressive as creating it in the first place.
Above I spoke of a truly minimal 187-mer replicase, and then of a slightly larger genome (2,587 bases) capable of translating from the RNA world to an RNA-plus-protein world. The next step up the ladder of replexity is to an even larger genome, one capable of high-fidelity replication and using DNA in place of RNA. In going from 187 to 2,587, and then to 113,000 bases, we see more than just an increase in complexity of the genome. We see an expansion of the alphabet from four bases to twenty more letters in the form of amino acids. (Each amino acid has its own one-letter code; phenylalanine, for example, is F, leucine is L, and so on.) This addition of a new polymer class (i.e., amino acids strung together into proteins) greatly expands the range of folding, catalysis, and functionality in general. The two standard base pairs and occasional nonstandard pairs (in
Figure 1.4
) of the RNA world basically look and act chemically neutralâflat inert plates. The twenty amino acids embody new positive, negative, and variable charges as well as highly reactive sulfur atoms that are all foreign to the A, C, G, U nucleotides of RNA. Furthermore, proteins have roughly 20*20 = 400 possible amino acid pairings (20*20/2 + 10 = 210 unique pairings, actuallyâincluding self-pairs), each pair having a greater diversity of interaction angles and chemistries than RNA possesses.
In line with our single-minded quest to increase diversity, it's relevant to ask how we could expand this raw treasure trove of replexity in the future. Just adding mirror nucleotides and mirror amino acids would essentially double the number of these basic units (monomers) from twenty-four (4 nucleotides + 20 amino acids) to forty-seven (by adding 4 more ribo-nucleotides and 19 more amino acids [not 20, however, since, as noted in
Chapter 1
, glycine is so simple that it is its own mirror image]). These mirror monomers combine into linear polymers (RNA and proteins), and even though they have radically new characteristics, these RNA and protein polymers are nevertheless completely predicable in terms of
their binding and catalysis properties so long as we know the properties of the original (nonmirror) versions.
Then, as an even more radical advance in complexity than creating a separate world of mirror amino acids, we could create proteins made of a mixture of
both
types of amino acids, the standard twenty plus the nineteen mirror versions, for a grand total of thirty-nine. (As we saw just above, since glycine is its own mirror version it does not constitute an additional amino acid.) For proteins of length N, we could make 20N possible chains using the standard set and 39N possible proteins using the expanded, “mirror” set of amino acids. Initially we would keep the systems either pure standard or pure mirror, since putting both types of amino acids into a cell without the benefit of more knowledge than we have now would almost certainly be toxic to a standard living cell. Why? Well, we know that as a result of billions of years of evolution and selection, pure standard proteins work correctly, and we know that pure mirror proteins fold predictably, but a mixture of the two would yield truly new folds, which we can't yet reliably predict. So for the time being we have been limited to
either
the twenty standard amino acids
or
the nineteen additional mirror versions, and could not use a mixture of both.
On the top left of
Figure 3.1
, the amino acid F is attached to the only appropriate tRNA using an amazing minimal 47-mer synthetic ribozyme capable of catalyzing the addition of any amino acid to any tRNA. In a cell, twenty protein enzymes (synthetases) discriminate among the thirty-two tRNAs to bond the correct amino acid to the appropriate tRNA. But in the lab, by contrast, the ribozyme is specific only if a researcher is putting the correct pure amino acid and pure tRNA in the same reaction tube.
And here we come to the climax of the mirror-world creation story. For this very promiscuous nature of the artificial ribozyme bonding amino acids to RNAsâthe same ribozyme catalyzes the bonding of
any
amino acid to
any
tRNAârepresents the key step in the plan to construct the mirror world introduced in
Chapters 1â2
. The artificial ribozyme will accept any amino acid, including even mirror amino acids, while the natural synthetases have evolved to avoid the use of more than one amino acidâincluding mirror amino acids.
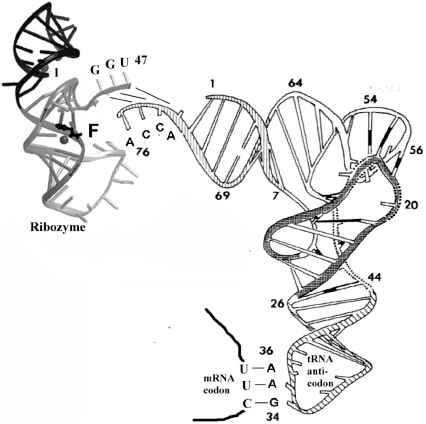
Figure 3.1
The genetic code is being read and decoded at every moment in every living cell on earth. There are two key steps in this decoding process. The first step is the bonding of each amino acid to an appropriate tRNA, and the second step is having that tRNA lining up on the messenger RNA (mRNA) conveyer belt in the ribosome, one triplet codon at a time. The first step is illustrated above with the amino acid phenylalanine (F) being added to the end of the tRNA (at position 76) under the catalytic direction of a synthetic (unnatural) ribozyme (upper left). The ribozyme mainly recognizes the tRNA by three base pairs: ACC (73 to 75) of the tRNA, and GGU (45 to 47) of the ribozyme, by the base pairing rules (A:U and C:G, in
Figure 1.4
). The second step is visualized in the lower right where three base pairs form between an mRNA codon (UUC) and a tRNA anticodon (GAA 34 to 36), again by the same base pairing process (
Figure 1.4
). (An anticodon is the sequence of three nucleotides in a tRNA molecule that corresponds to a complementary codon in an mRNA molecule.) The backbones of these two interacting RNAs are long curved lines, and the base pairs are represented as short straight lines.